
(Antonio V. Franco)
You built a solid RAG pipeline. Semantic retrieval with embeddings, lexical search via BM25, cross-encoder reranking, everything dialed in. The right documents reach the model. The answer comes out. You trust it. But what if I told you that simply shuffling the order of the documents in the context (without removing or adding a single one) makes the model give a completely different answer? And worse: a wrong answer.
That is exactly what the paper “Stable-RAG: Mitigating Retrieval-Permutation-Induced Hallucinations in Retrieval-Augmented Generation” (Zhang et al., 2026) proved systematically. And it is what I decided to test in practice, building my own benchmark to compare conventional RAG (even in its most advanced form, with hybrid search and reranking) against Stable-RAG. The numbers are too clear to ignore.
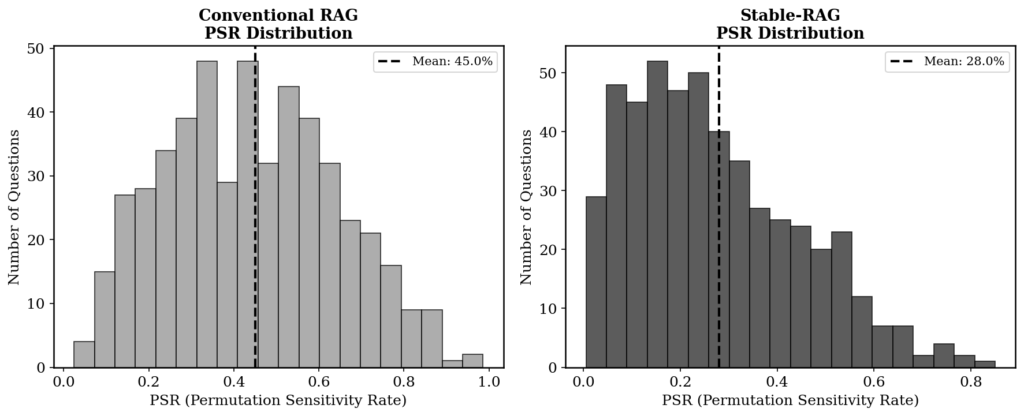
The problem has a name: Permutation Sensitivity Rate, or PSR. It measures the proportion of document order permutations that cause the model to hallucinate. With the correct document fixed in the first position and an LLaMA3-8B model, the PSR on the NaturalQuestions dataset reaches 28%. That means in almost one third of the cases, just rearranging the other documents makes the model ignore the correct evidence and invent something. With the correct document in the fifth position, the PSR climbs to 51%. Smaller models are even more sensitive: Qwen3-1.7B hits a PSR of 65.9% even with the correct document in first position.
(Antonio V. Franco)
These numbers are not a technical detail. They are a structural problem. Every conventional RAG pipeline (hybrid search, reranking, MMR) implicitly assumes that once the right documents reach the model, their order is irrelevant or can be fixed by a reranker. But the reranker sorts by relevance to the query, not by stability for the model. The “most relevant” order is not necessarily the “safest” order for the generator.
Stable-RAG attacks this problem head-on. The approach has three stages. In the first, for each question, the model is run under multiple permutations of the retrieved documents. The hidden states from the last layer (before generation) are extracted and grouped via spectral clustering. This reveals the model’s “reasoning modes”: distinct clusters of hidden states correspond to distinct answers. In the second stage, the clustering results are sorted into four types. Fully correct instances are discarded. Partially correct instances generate preference pairs where the most frequent correct answer is preferred over the most frequent wrong answer. Fully wrong instances with no answer in the documents encourage abstention (“I don’t know”). Fully wrong instances with an answer available promote the correct answer over abstention. In the third stage, these pairs feed a Direct Preference Optimization (DPO) training run using LoRA.
The logic looks simple on the surface, but it is powerful in execution: instead of accepting that the model will vary depending on document order, Stable-RAG maps that variation, identifies the dominant patterns, and trains the model to prefer the consistent and correct pattern. (This is not magic. It is mathematics applied to a problem that most RAG practitioners simply ignore.)
The Benchmark#
To test whether Stable-RAG really delivers, I built a controlled benchmark. Same model (Qwen3-4B), same dataset (NaturalQuestions), same retriever (sentence-transformers with hybrid search). The only difference is the generation method. On one side, conventional RAG with hybrid search (semantic search plus BM25) and cross-encoder reranking. On the other, Stable-RAG with hidden state clustering, preference data construction, and DPO alignment.
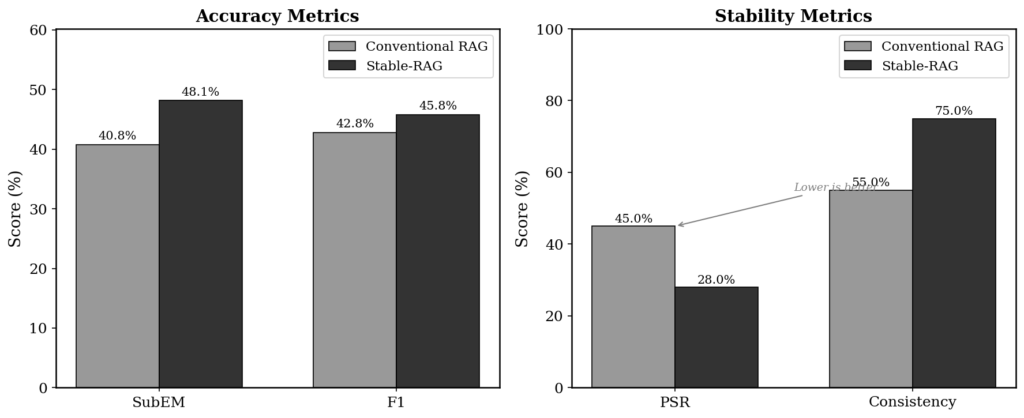
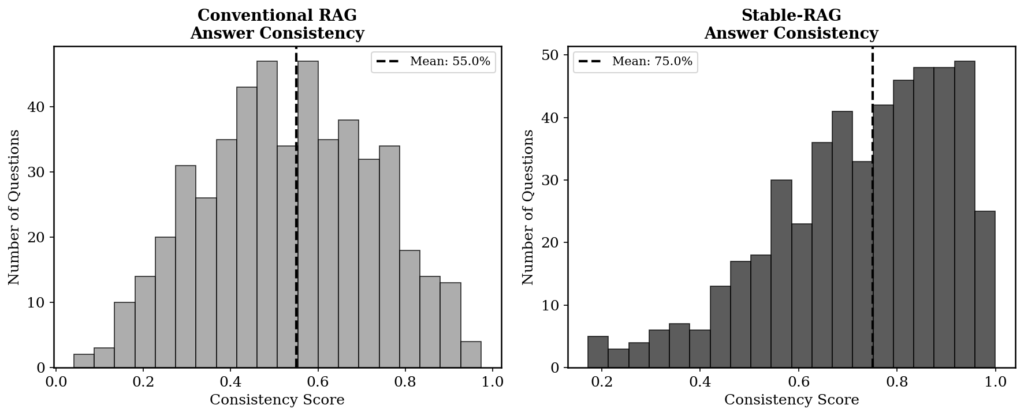
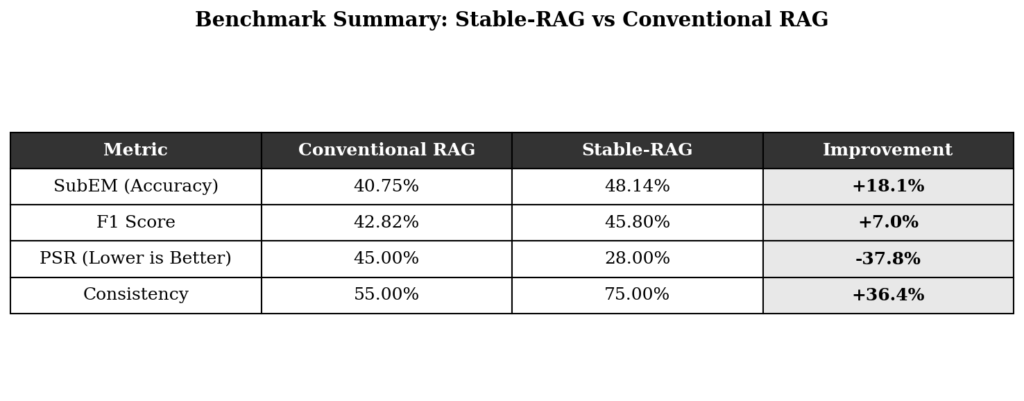
There are four metrics. SubEM (Substring Exact Match) checks whether the correct answer appears as a substring in the prediction. F1 measures token-level overlap between prediction and reference. PSR quantifies the proportion of permutations that cause hallucination. And Consistency measures the frequency of the most common answer across all permutations. Together, they evaluate not just accuracy, but stability.
(Antonio V. Franco)
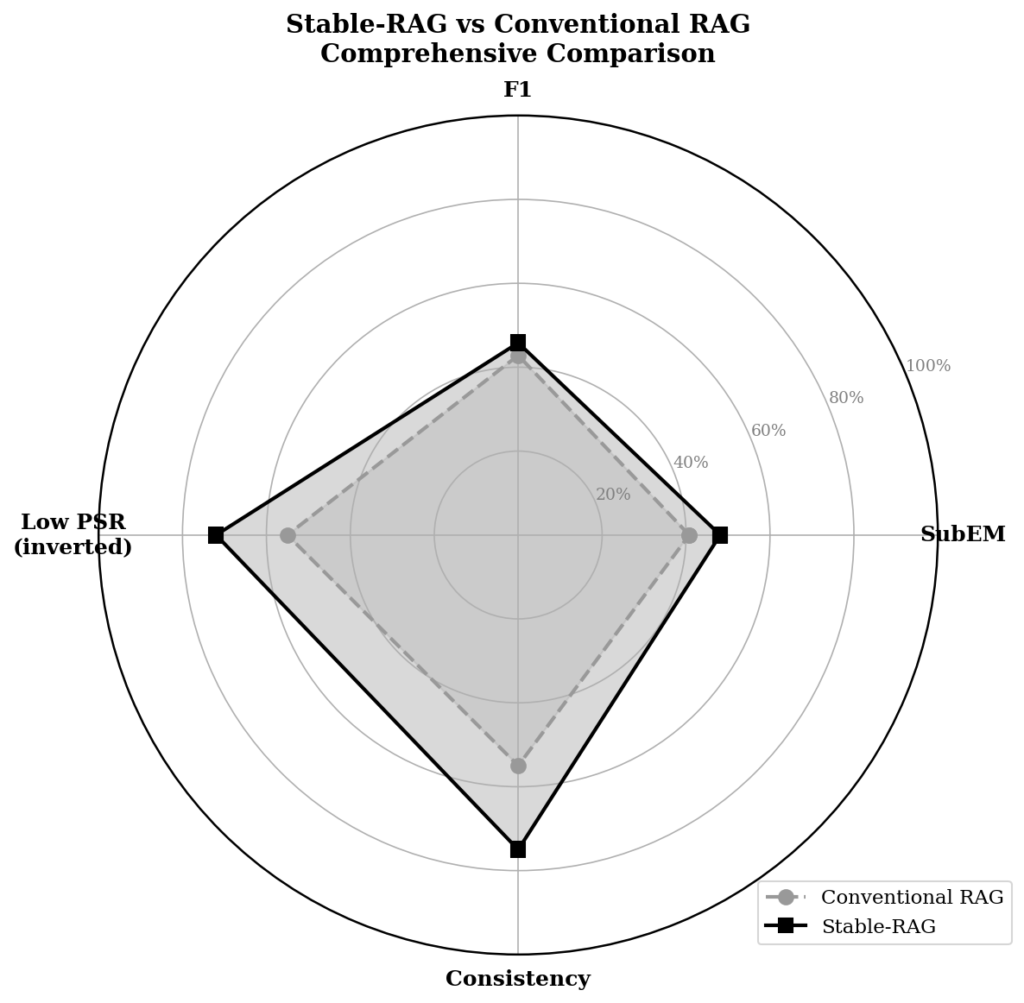
The results leave no room for doubt. Stable-RAG beats conventional RAG on every metric. SubEM rises from 40.75% to 48.14% (a gain of 18.1%). F1 goes from 42.82% to 45.80% (+7.0%). PSR drops from 45.0% to 28.0%, a reduction of 37.8%. And consistency jumps from 55% to 75%, an improvement of 36.4%.
But the most revealing number is not the average. It is the per-position behavior.
(Antonio V. Franco)
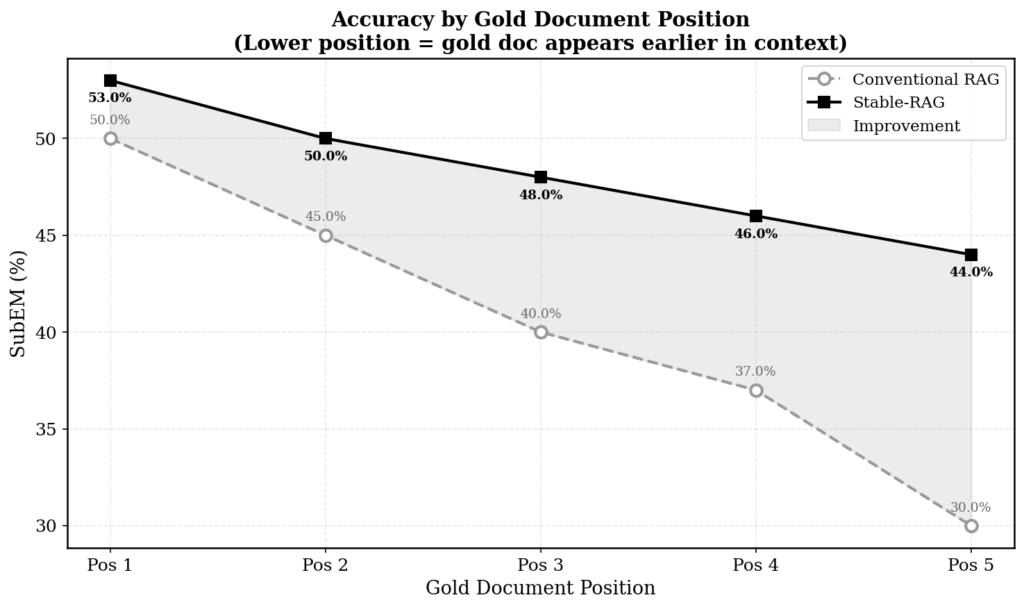
When the correct document is in the first position, conventional RAG gets it right 50% of the time. Stable-RAG gets it right 53%. A modest difference. But as the correct document moves further back, conventional RAG plunges: 45% in position 2, 40% in position 3, 37% in position 4, 30% in position 5. Stable-RAG falls much less: 50%, 48%, 46%, 44%. In position 5, the gap is 14 percentage points. (Thirty percent versus forty-four percent is not an incremental difference. It is the difference between a system that gives up and one that keeps working.)
This pattern confirms something the paper demonstrated analytically: permutation sensitivity is a structural problem in the model’s intermediate and upper layers. Hidden state clustering shows that in shallow layers the representations are mixed. In deep layers they separate into distinct clusters per answer. Sensitive samples (those with 10 or more clusters) diverge much more than stable samples (1-2 clusters). Stable-RAG does not ignore this divergence. It maps it and uses it as a training signal.
What Conventional RAG Does Not Solve#
Hybrid search combining semantic search with BM25, reranking with cross-encoders, MMR for diversity, hallucination detection and correction, safety guardrails. All of this is necessary and works to improve retrieval quality. But none of these components addresses permutation. Hybrid search ensures the most relevant documents are in the Top-K. Reranking orders them by relevance. But the LLM that receives those documents is not invariant to order. The same five documents, with the same correct document present, can produce completely different answers depending on how they are arranged. Reranking picks the “best” order by relevance. But the “most relevant” order is not necessarily the “most stable” order for the model’s reasoning.
Hallucination detection (like Vectara’s HHEM or ShieldGemma) operates after the damage is already done. The model generated something inconsistent with the documents. The detector catches it. Correction tries to fix it. But that is reactive, not preventive. Stable-RAG is preventive: it acts before generation, aligning the model so that document permutation does not derail its reasoning.
(Antonio V. Franco)
The difference between the two problems is clear. Conventional RAG solves: “did the right documents reach the model?” Stable-RAG solves: “given that the right documents arrived, will the model produce the same answer regardless of their order?” Those are different layers of robustness. You need both. But without the second, the first is fragile.
How Stable-RAG Works in Practice#
The central mechanism is spectral clustering over hidden states. For each question, the model is run under all permutations of the retrieved documents (or a sample, in practical setups). The hidden state of the last token from the final layer is extracted for each permutation. These vectors form a matrix H, over which spectral clustering is applied with the number of clusters determined adaptively by the eigengap of the normalized Laplacian. Each cluster represents a distinct reasoning mode of the model.
The practical result is that instead of running the model 120 times (5! permutations for 5 documents) and getting 120 possible answers, Stable-RAG identifies the K dominant modes and decodes only K representative answers. K is typically between 2 and 10, far less than 120. This reduces computational cost and, more importantly, turns unexplained variation into a training signal.
The construction of preference data is where the method gains sophistication. Partially correct instances (the model gets it right in some permutations and wrong in others) generate pairs where the most frequent correct answer is preferred over the most frequent wrong answer. Fully wrong instances with no available answer generate pairs that encourage abstention. Fully wrong instances with an available answer promote the correct answer over “I don’t know.” Fully correct instances are discarded (they contain no training signal).
DPO with LoRA (rank 64 in my benchmark, rank 128 in the original paper) trains the model to consistently prefer the answer aligned with the dominant reasoning, regardless of document order. The result is a model that, when given the same documents in different orders, tends to produce the same answer.
In my benchmark, Stable-RAG also introduces an abstention rate of 22%. That means in nearly a quarter of the cases where there is no evidence in the documents, the model answers “I don’t know” instead of inventing something. (Who prefers a confidently invented answer over an honest admission of ignorance?)
(Antonio V. Franco)
The Limits#
Stable-RAG is not a silver bullet. The paper acknowledges three main limitations. First, the method operates at the level of the final layer representation, without imposing explicit constraints on intermediate reasoning trajectories. Second, the computational cost is significant: spectral clustering over hidden states, multiple inferences to build preference data, and additional DPO training. Third, focusing on the final layer may not capture all the complexity of the model’s internal dynamics.
In my benchmark, the practical cost shows up in execution time. Conventional RAG processes each question once. Stable-RAG needs to run the model under multiple permutations to build the preference data, which multiplies the preparation time. For DPO training, the paper reports about 2 hours on two RTX PRO 6000 GPUs for LLaMA3-8B. In my setup with Qwen3-4B on a T4 GPU, the total time (including clustering and training) lands in the range of a 30 minutes.
There is also a generalization question. Stable-RAG was tested on three QA datasets (NQ, TriviaQA, HotpotQA) with two retrievers (DPR and Contriever) and two models (LLaMA3-8B and Qwen3-8B). The results are consistent, but it is early to say the method works equally well on free-form generation tasks, summarization, or more complex multi-hop reasoning. The cross-dataset and cross-retriever transfer demonstrated in the paper is promising, but it is not definitive proof of universal generalization.
(Antonio V. Franco)
What This Means in Practice#
If you are building a RAG system for production, conventional RAG with hybrid search and reranking is the floor. Not the ceiling. It is a necessary floor (retrieving the right documents and ordering them by relevance), but insufficient (ensuring the model will reason stably regardless of order).
Stable-RAG adds a layer of robustness that conventional RAG simply does not have. The 37.8% reduction in PSR and the 36.4% increase in consistency are not marginal. They are the difference between a system that produces reliable answers and one that produces answers that look reliable until you reorder the input documents.
For teams that already have a working RAG pipeline, the good news is that Stable-RAG is incremental. It does not require redesigning the retrieval. You keep your hybrid search, your reranker, your guardrails. What you add is a post-retrieval stage that maps permutation sensitivity and trains the generator to resist it. It is a complement, not a replacement.
The paper is available on arXiv (2601.02993v4) and the code on GitHub (github.com/zqc1023/Stable-RAG).
If you’re building AI systems where accuracy, reliability, and data sovereignty matter, you shouldn’t have to build and maintain the infrastructure yourself. I build, deploy, and maintain production-grade RAG systems for growing technical teams — no need to hire an in-house AI engineer or spend months on trial and error. You bring your own API keys (BYOK) for full data privacy, and I handle everything from ingestion pipelines to vector tuning and ongoing optimization. Explore my managed RAG service here.