(Antonio V. Franco)
If there is one thing I have learned over the last three years, it is that technology does not forgive naivety. And I was naive (quite expensively, in fact).
In 2023, when ChatGPT exploded and the entire world woke up to the existence of large language models, I did exactly what everyone else did: I threw myself headfirst into the giants’ race. It was as if there were a silent, collective competition to see who could accumulate more parameters, more context tokens, more raw computational power. If your company was not paying a fortune in monthly API calls or building an entire GPU cluster to run the model with the most zeros in the spec sheet, you were “falling behind.” That was the mantra repeated in every keynote, every corporate blog post, every networking conversation about AI.
I bought into that narrative. I bought API credits, I built the infrastructure, I convinced stakeholders that the investment was worth it because “it was the future.” And for a while, it worked, or at least it seemed to work. The demos were impressive. The initial results were promising. The general excitement masked the operational details that only show up when real scale starts knocking on the door.
Today, in 2026, I look back, revisit the decisions I made, analyze the cold hard numbers of my infrastructure, and I ask myself: what was it all for?
This is not a rhetorical question. It is a question I wish someone had asked me back in 2024, when I was at the peak of my enthusiasm with massive models. Because the answer, after a lot of experimentation, a lot of headaches with infrastructure costs inflating month after month, and many frank conversations with people who are building real things in production, is simple and perhaps a bit uncomfortable to admit: the race of gigantic LLMs is over. And anyone who has not realized this yet is still paying dearly, literally, monthly, with no proportional return.
I am not saying this because of a trend or because I read some sensationalist article. I am saying it because I lived both sides of this coin. And the side I live on today, with specialized SLMs running on my own infrastructure, is incomparably better, in cost, in performance, in autonomy, and yes, in results.
When the chart stopped climbing#
Let us be honest about what happened between 2023 and 2025. The quality of language models experienced exponential growth that few in the industry truly expected, and that even fewer were prepared to sustain long-term. Every new release from the big tech companies brought real, measurable leaps: better logical reasoning, fewer hallucinations on complex tasks, significantly more sophisticated context understanding, the ability to follow multi-layered instructions without losing the thread. It was genuinely impressive. There was no way not to be captivated by what was happening.
But in 2026, something changed. Or rather, something did not change, and it is precisely this absence of change that is the problem.
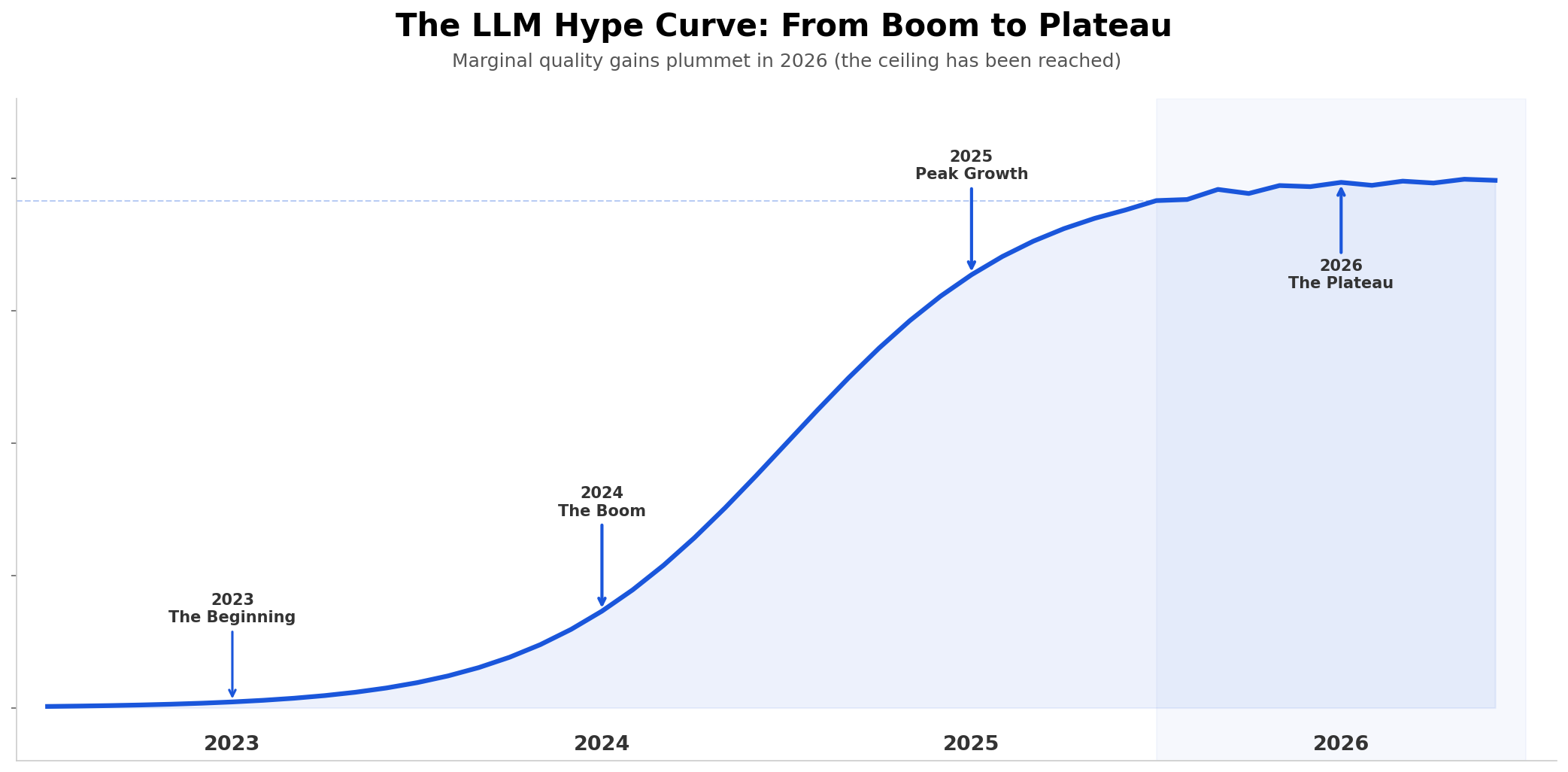
(Antonio V. Franco)
The chart above is not my opinion. It is the cold, impersonal reading of the data. The quality curve of LLMs followed a pattern that any technology student recognizes immediately: the classic S-curve of disruptive technology adoption. Slow initial phase, when few believe and results are inconsistent. Explosive growth, when leaps are visible and everyone wants in. And plateau, the point where marginal gains become so small that they no longer justify additional investment. And we are, unequivocally, at the plateau.
Since the beginning of 2026, the marginal quality gains between one version and another of any commercial model are, at best, marginal. GPT-5 is not significantly better than GPT-4 Turbo for the overwhelming majority of real use cases that companies face day to day. The newest Claude Opus does not solve problems that the previous version could not solve, it merely solves them with a bit more polish in the response. The latest Gemini? More of the same, with different marketing.
Think about what this means in practice: if you are paying 3x more per token for a new model version and the quality of the result improves by 2-3%, the math simply does not add up. And when I say 2-3%, I am not exaggerating, I am being generous. For tasks like document classification, entity extraction, structured report generation, and sentiment analysis, the difference between the previous version and the current one is statistically insignificant in most independent benchmarks.
LLMs, in 2026, have nothing left to surprise us with. And this should be liberating, it should mean that we can finally stop treating language models as mystical oracles and start treating them as tools. But for many people, especially those who built their entire AI strategy around giant LLM APIs, this reality is cause for panic. Because admitting that the plateau has been reached means admitting that the strategy was wrong.
And I understand this resistance. I felt it firsthand. But the math does not lie, and my infrastructure numbers from the last quarter were the push I needed to finally accept the obvious.
The myth of “bigger is better”#
For two full years, the industry sold (and bought) the narrative that the model with more parameters was automatically the best model. This logic was perfectly comfortable for the big tech companies, because it justified billion-dollar investments in data centers that, let us be honest, were much more about infrastructure than about artificial intelligence itself. And it was convenient for companies of all sizes that wanted “innovation” without needing to think much about which specific problem they were trying to solve.
It is much easier to say “we are using the most powerful model on the market” than to explain why your specific use case needs a customized approach. The first sounds like technological leadership. The second sounds like work, and work is hard work.
But operational reality is completely different from what the keynotes promise.
When you put a 1-trillion-parameter model to solve a specific problem (say, classifying legal documents by clause type, generating financial reports from raw ERP data, or answering technical questions about a software product based on internal documentation) you are, in practice, using a cannon to kill an ant. And I am not using that metaphor lightly: I am talking about real costs, real latency, real energy consumption.
Here comes the first uncomfortable truth that I took too long to accept: for 95% of enterprise use cases, a giant model does not deliver a proportionally better result than a smaller, specialized model. The quality difference is marginal, we are talking about percentage points in benchmarks that, in practice, do not translate into measurable business impact. But the cost difference? The cost difference is brutal. It is the difference between an API bill that fits in a department budget and one that requires CFO approval.
And there is a detail that nobody mentions in the keynotes: larger models are not just more expensive, they are slower, harder to fine-tune, more opaque in their errors, and more dependent on infrastructure that most companies simply do not have. When your 500B parameter model hallucinates, you cannot fix its behavior without retraining the entire monster. When a 7B parameter SLM makes the same error, you adjust the fine-tuning dataset and resolve it in an afternoon.
Why open source won (and won decisively)#
One of the most impressive (and, in my opinion, underestimated by mainstream tech media) shifts I witnessed was the meteoric rise of open source models. If you go back to 2023, using an open source model was practically synonymous with “not worth taking seriously.” It was what underfunded startups did while waiting to afford “something real.” In 2024, it was already an option “interesting for those who cannot afford commercial models.” And in 2026? In 2026, it is the obvious, rational, and economically superior choice for anyone who understands what they are doing, and who has real numbers to prove it.
Models like Llama, Mistral, Qwen, and the hundreds of community fine-tuned variants have, over the past two years, reached a level of maturity that, in day-to-day practice, rivals (and in many cases surpasses) proprietary models for most of the tasks companies actually need to solve. And most importantly: they have structural advantages that commercial models simply cannot offer, no matter how much marketing they put behind them.
No vendor lock-in. Your model is yours, period. You do not depend on the availability of a third-party API, on arbitrary pricing changes that can happen from one month to the next, or on corporate decisions from some Silicon Valley company that can decide to discontinue the service your entire operation depends on. How many times have I seen companies caught off guard by 200-300% API price increases? More than I can count. With open source, this risk simply does not exist.
Real privacy, not marketing privacy. Your data does not leave your infrastructure. For sectors like healthcare, finance, legal, and government, this is not a “competitive differentiator” to put on a slide, it is a regulatory requirement. LGPD, GDPR, HIPAA, all these regulations make the use of commercial APIs a compliance nightmare that many prefer to ignore until the fine arrives. With open source models running locally, privacy is not a promise, it is a natural consequence of the architecture.
Total customization without restrictions. Fine-tuning, RAG, quantization, pruning, knowledge distillation, you have complete control over every aspect of the model, from the training dataset to how it responds in production. Want to train the model with data specific to your industry? Do it. Want to adjust its behavior for a specific communication tone? Do it. Want to optimize it to run on specific hardware? Do it. With commercial models, you are hostage to what the API allows. With open source, the limit is your technical creativity.
Predictable and controllable cost. Once the model is deployed on your infrastructure, the cost is infrastructure, and infrastructure is something you control. No billing surprises at the end of the month, no artificial rate limits that freeze your operation during demand peaks, no “oops, we raised the price because our shareholders want more profit.” The cost is what you spend on hardware and energy, and that is predictable, planable, and optimizable.
The narrative that “open source is not good enough for production” died in 2025, and it died loudly. Anyone who still repeats that phrase in 2026 is either genuinely out of date (and should update themselves before making technical decisions) or has some direct commercial interest in keeping this illusion alive. Because the only person who benefits when you believe you need to pay for an API is the one selling the API.
SLMs: the silent revolution nobody saw coming#
And here we finally reach the core of the matter. If giant LLMs have hit the quality plateau and open source models are already mature enough for production, what is the logical next step? What is the missing piece in this puzzle?
Specialized Small Language Models (SLMs).
While the collective attention of the industry (media, investors, CTOs, conferences) was hypnotized by models with hundreds of billions of parameters, a quiet current of researchers, engineers, and companies was proving something radically different: smaller models (in the range of 1B to 13B parameters), trained specifically for narrow, well-defined domains, deliver consistently superior results to generalist LLMs on the tasks that actually matter for business. And they do it with a fraction (a tiny fraction) of the computational, financial, and operational cost.
This is not theory. This is not academic research disconnected from reality. This is production. This is people running this on real servers, with real data, solving real problems, and saving real money in the process.
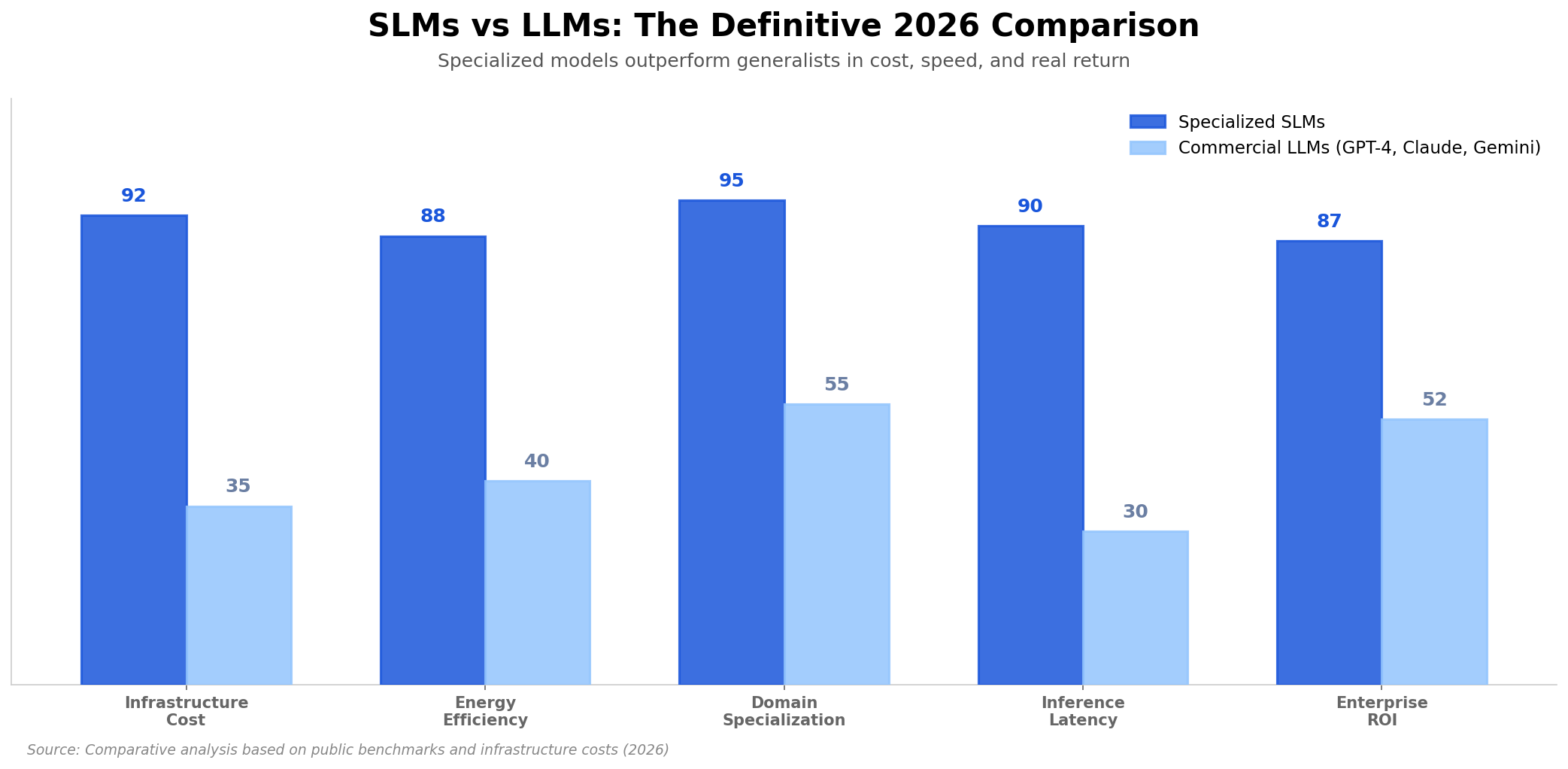
(Antonio V. Franco)
The numbers in the comparison above speak for themselves, but I will highlight (and expand on) what impacts me most in practice, because each of these points represents a decision I made wrong in the past and now make in a completely different way.
Infrastructure cost. This is the most visceral and immediate difference. A specialized SLM can run on a single consumer-grade GPU (an RTX 4090, for example) or even on CPU with adequate quantization (4-bit or even 2-bit, depending on the task). The hardware cost for this is a fraction of what you spend on a single commercial API call at volume. A commercial LLM, on the other hand, requires entire clusters of enterprise-grade GPUs or APIs with per-token costs that scale exponentially as volume grows. I have seen API bills that exceed the salary of a senior developer per month. An SLM running locally? The cost is electricity and hardware depreciation.
Domain specialization. This is the point people most underestimate. An SLM trained specifically to process Brazilian legal contracts, for example, will understand nuances of legal terminology, clause structure, and normative references that a 1-trillion-parameter generalist LLM simply does not have in its training data, because its training data is generic, trained to be “good at everything” and consequently “exceptional at nothing.” It is not a matter of “intelligence” or “cognitive capacity” of the model. It is a matter of focus. A 30-year tax law specialist will give a better answer about taxes than a brilliant generalist who knows a little about everything. The same principle applies to models.
Latency. This is the point that separates viable products from unviable ones. Inferring with a 3B parameter model is orders of magnitude faster than with a 500B one, not just in absolute time, but in terms of consistency. An SLM runs in milliseconds consistently. A giant LLM, depending on the load of the API server, can vary from hundreds of milliseconds to several seconds. For real-time applications (customer service chatbots, recommendation systems, data stream processing) this difference is not a technical detail you mention in code review. It is what determines whether your product works or not in the end-user experience.
Enterprise ROI. And this, finally, is the point that matters most to real decision-makers, CEOs, CFOs, CTOs. The return on investment of a specialized SLM is incomparably superior to that of a generalist LLM, and the math is too simple to ignore: lower infrastructure cost (70-95% lower), lower latency (5-10x faster), higher accuracy in the specific domain (because the model was trained for that). When you put all of this on paper, the decision stops being technical and becomes obvious.
The real economics#
There is an angle to this discussion that I need to address because it is where most companies bleed money without realizing it: the hidden costs of commercial LLMs.
When you calculate the cost of an LLM API, most people only look at the price per token. And that makes sense, it is the most visible number, the one that appears on the invoice. But that is only the tip of the iceberg.
The real cost includes engineering time spent adapting prompts to work around model limitations. It includes the cost of dealing with rate limits that freeze your operation during peak hours. It includes the cost of compliance when your sensitive data passes through third-party servers. It includes the cost of not being able to fine-tune the model because the API does not allow it. It includes the cost of being hostage to pricing changes you cannot control. It includes the cost of inconsistent latency that degrades the user experience.
When you add all of this up (and I added it up, with a spreadsheet, with real numbers from my operation) the total cost of a commercial LLM is easily 5x to 10x higher than the per-token price suggests. And that is the cost nobody tells you about in the sales slides.
With specialized open source SLMs, all of these hidden costs simply disappear. You control the model, you control the infrastructure, you control the data, you control the costs. And when something goes wrong, you fix it, you do not open a support ticket and hope for a response within 48 hours.
What I do differently now (and what I recommend)#
After burning an amount of money that still hurts to remember today on commercial LLM APIs, and after trying to deploy gigantic models on my own infrastructure (which was, in retrospect, a decision as naive as it was expensive), my approach changed radically. Today, my playbook for any project involving AI is completely different from what it was two years ago. And the results speak for themselves.
Define the domain with surgical precision. What exactly does the model need to do? The more specific you are in this definition, the better the final result will be. “Sentiment analysis” is too broad, it is the kind of definition that leads you to hire a cannon to kill an ant. “Classification of telecom customer complaints into network, billing, and support categories, with urgency identification” is the kind of definition that allows you to train an SLM that actually solves the problem. Specificity is not bureaucracy, it is the foundation of everything that comes after.
Start with an open source base model appropriate to the problem. Llama, Mistral, Qwen, all have versions with 3B to 13B parameters that are excellent starting points for the overwhelming majority of use cases. The temptation to start with the largest available model is real, but it is a trap. Do not start with the largest. Start with what makes sense for your specific problem, for your data volume, for your available infrastructure. You can always scale up later, but starting too big is the mistake I see people make most often, and it is the most expensive mistake to correct.
Fine-tune with real data from your domain, and do it right. Here is the secret that big tech companies definitely do not want you to discover: a 7B parameter model fine-tuned with a high-quality dataset, specific to your domain, with real examples of the problems you face, will consistently outperform a 500B parameter generic model on your specific task. And it will cost, at most, 1% of the price. The secret is not in the size of the model, it is in the quality and specificity of the training data. A small, well-curated dataset is worth more than a large, generic one. Always.
Deploy locally, whenever humanly possible. Unless you have very specific global scale requirements that justify the use of external APIs (and believe me, this is rarer than people think) deploying locally is the right decision in practically every scenario. It eliminates recurring API costs, completely removes vendor lock-in risks, gives you total control over performance and latency, and guarantees absolute data privacy. The barrier to entry for local deployment has dropped dramatically over the past two years. Tools like Ollama, vLLM, and TGI have made the process accessible even for small teams. There is no longer any technical excuse not to do it.
Monitor, measure, and iterate continuously. The definitive advantage of having your own model is that you can iterate continuously, without asking anyone for permission. New data arrived in your dataset? Incremental fine-tune in a few hours. New business requirement emerged? Adjust the prompt engineering or restructure the RAG pipeline. The model started degrading on a specific metric? Identify, fix, redeploy. You are not hostage to a third-party company’s roadmap that prioritizes shareholder interests over yours. You are in command, and that changes everything.
Build a culture of measurement, not faith. One of the mistakes I made in the past was treating model output as something almost mystical, “the model said it, so it must be right.” That is naive. Every model makes errors, every model hallucinates to some degree, every model has biases in its training data. The difference is that, with your own SLM, you can measure, track, and correct these errors systematically. Build automatic evaluation pipelines, monitor quality metrics in production, and treat the model as what it is: a software component that needs testing, metrics, and iteration.
What companies that insist on giant LLMs are losing#
And I am not just talking about money, although money is, indeed, the most visible part of the problem. What companies that insist on commercial LLMs are losing goes far beyond the monthly bill.
They are losing speed. Every time they need a change in model behavior, an optimization in latency, an adjustment in cost, they need to wait for the API-owning company to decide to implement it, or, more likely, not implement it. Meanwhile, the competitor running their own SLMs has already adjusted, already deployed, already reaping the benefits.
They are losing autonomy. When you depend on a commercial API, every strategic decision you make (about pricing, about usage limits, about available features, about deployment regions) is made by someone else, at another company, with different interests, in a different time zone. When the model changes without notice, you adapt. When the price rises arbitrarily, you swallow it. When the API goes down in the middle of a critical operation, you wait and pray. That is not infrastructure, that is gambling.
They are losing the capacity to innovate. Because when you are hostage to a closed platform, your innovation is limited by what the platform allows. Want to create a custom RAG flow with custom retrievers? The API may not support it. Want to integrate the model with a proprietary data pipeline? The API may have limitations. Want to fine-tune for an ultra-specific use case? The API simply does not allow it. Every “no” from the API is a “no” to your innovation.
With specialized SLMs, you are in control. And in 2026, in a market where execution speed is what separates leading companies from following ones, control is not a luxury, it is an absolute survival necessity.
Companies that have already migrated to specialized SLMs (and I have spoken with dozens of them over the past few months) report consistent reductions of 70% to 95% in total AI infrastructure costs, with equal or superior results for their specific use cases. And when I say “total costs,” I am including everything: hardware, energy, engineering, maintenance. This is not “marginal optimization”, it is real operational transformation. It is the difference between an AI department that is a cost center and one that is a profit center.
The future is smaller, more focused, and smarter#
The era of gigantic LLMs as the standard was a necessary chapter in the history of artificial intelligence, without these models, we would not have gotten to where we are today. But it is a chapter that has already turned the page. In 2026, continuing to invest heavily in generalist models with hundreds of billions of parameters to solve specific problems is not innovation. It is stubbornness disguised as technological leadership. It is continuing to run in a marathon that has already ended.
The future (the real, practical, economic, and technically superior future) belongs to those who understand that the differentiator is no longer how powerful a model is, but how well it solves the specific problem you have. And for that, specialized SLMs are the definitive answer. Lower infrastructure cost. Greater energy and computational efficiency. Total control over data and behavior. Consistently superior results in the specific domain. Iteration speed that commercial models simply cannot match.
The question we should be asking is no longer “what is the most powerful model?” That question lost relevance when the plateau was reached. The right question (the question that will define who leads and who falls behind in the coming years) is “which model solves my problem with the best cost-benefit, on my infrastructure, with my data?”
And the answer, in 2026, is almost always the same: a specialized SLM, running open source, on your infrastructure, with your data, fine-tuned for your domain, iterated continuously based on your metrics.
Those who understand this first get ahead. I am not talking about an advantage of months, I am talking about an advantage of years. Because while some are paying fortunes in APIs for models that no longer evolve, others are building intelligent systems that evolve with the business, that cost a fraction of the price, that run with millisecond latency, and that do not depend on the goodwill of any third-party company.
And those who insist on the giants’ race will discover, on next month’s bill (and the quarter after that, and the one after that) that this race is over. That the plateau is real. And that they are paying alone for a marathon that everyone else has already crossed the finish line of.
The question is: will you keep paying, or will you finally take control?
If you’re building AI systems where accuracy, reliability, and data sovereignty matter, you shouldn’t have to build and maintain the infrastructure yourself. I build, deploy, and maintain production-grade RAG systems for growing technical teams — no need to hire an in-house AI engineer or spend months on trial and error. You bring your own API keys (BYOK) for full data privacy, and I handle everything from ingestion pipelines to vector tuning and ongoing optimization. Explore my managed RAG service here.