
(Antonio V. Franco)
Every time someone asks me whether it’s worth using GPT‑5.5 or Opus 4.7 in a RAG pipeline, I ask them the same question back: would you trust your most sensitive documents to a foreign company that’s subject to the CLOUD Act? The answer, almost always, is an uncomfortable silence. Commercial models are good. Really good. But RAG is, by definition, an operation that involves sensitive data (internal documents, contracts, customer histories, regulatory information) flowing through infrastructure you don’t control. Every query your system makes to the OpenAI or Anthropic API carries the retrieved context and the generated response along with it. And that context, almost all the time, contains exactly the kind of information that data protection regulations are trying to shield.
This is a structural issue. A RAG system works in three steps: retrieval, augmentation, and generation. Retrieval finds relevant documents in your vector database. Augmentation combines those documents with the user’s question. Generation uses an LLM to produce the final answer. In the first two steps, your data stays inside your infrastructure. In the third one, if you’re using a commercial API, your data travels to someone else’s servers, gets processed by models whose weights you’ve never seen, whose behavior you can’t audit, and whose data retention policies depend on contracts that can change overnight.
People usually bring up cost first in these conversations, and fair enough. But the argument that should drive the decision comes before that: data sovereignty. In any organization that handles sensitive information, the only way to ensure that data isn’t accessed by foreign authorities, isn’t retained for training purposes under policies that shift every quarter, and isn’t monetized in ways you never agreed to, is to keep processing inside infrastructure you audit, access, and modify. An open‑source LLM, hosted on‑prem or in a private cloud, meets that requirement. Commercial models, no matter how capable, never will.
The hidden cost of commercial APIs#
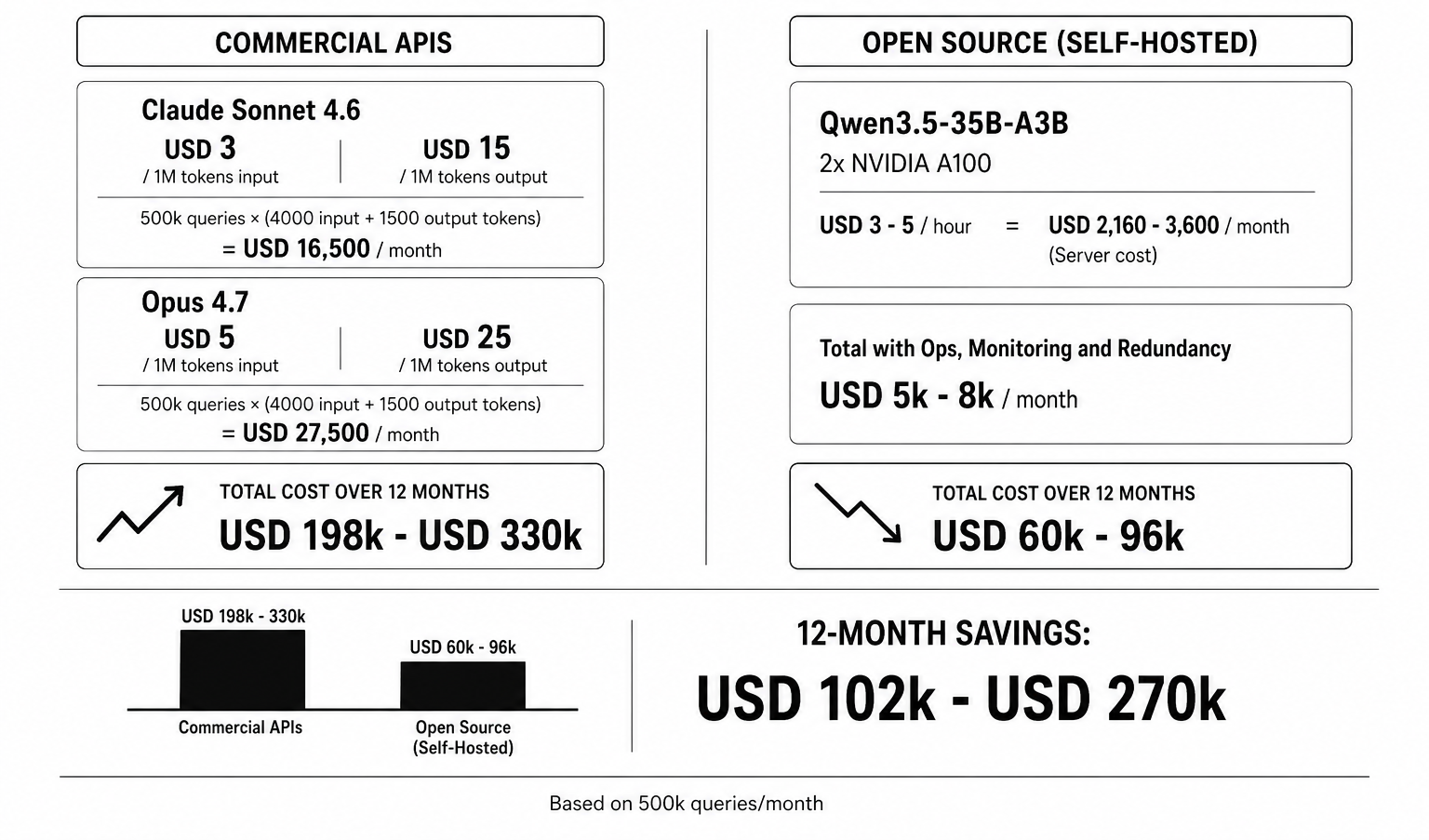
Let’s run the numbers. If you process 500,000 queries per month with an average of 4,000 input tokens and 1,500 output tokens per query, using Claude Sonnet 4.6 at $3 per million input tokens and $15 per million output tokens, you’re looking at roughly $16,500 a month just for inference. Switch to Opus 4.7, and it jumps to $27,500 monthly. Over twelve months, you’ve shelled out between $198,000 and $330,000 to rent compute you’ll never own. And if your traffic grows, that cost scales linearly with no ceiling. (If it doesn’t grow, you’ve got bigger problems than which model to pick.)
(Antonio V. Franco)
The alternative changes the math completely. A server with two NVIDIA A100 80GBs, rented for $3 to $5 an hour on RunPod or Vast.ai, runs Qwen3.5‑35B‑A3B (3 billion active parameters per token, native 262k context window extendable past a million, Apache 2.0 license) without paying a single cent per token. That server costs around $2,160 to $3,600 a month. Add operations, monitoring, and redundancy, and you’re in the ballpark of $5,000 to $8,000 monthly for infrastructure that handles the same volume with lower latency and no reliance on external connectivity. In six months, your own setup has paid for itself. In twelve, you’re saving over $100,000 a year.
The math is simple, and the industry has already figured it out. The 8.8 million downloads of Qwen3‑8B and the 9.2 million downloads of Llama 3.1 8B Instruct on HuggingFace aren’t hobbyist curiosity. Those are production deployments. Companies processing millions of queries a month have already found that the break‑even point between API and self‑hosting sits somewhere between 100k and 500k monthly queries (depending on the model and usage pattern). Beyond that, self‑hosting is always cheaper.
Embedding models add to the cost and make the gap even wider. OpenAI’s text‑embedding‑3‑small charges $0.02 per million tokens. That sounds like nothing until you index 10 million documents averaging 2,000 tokens each. With self‑hosting, Qwen3‑Embedding‑0.6B (5.8 million downloads, 32k context, support for 100 languages) processes the same documents for the cost of local compute. At the scale of billions of embeddings, the difference is ten to twenty times in favor of open source.
And then there’s the vector database. Managed Pinecone starts at $70 a month and scales into the thousands. Self‑hosted Milvus, written in Go and C++, runs on your own hardware and handles billions of vectors with native horizontal scaling via Kubernetes. Qdrant, in Rust, gives you advanced filtering with no license fees. Chroma, in Python, is great for quick prototyping. The difference isn’t just financial – it’s the difference between controlling where your data lives and outsourcing that decision to a company that changes prices and terms every time they update their roadmap.
The right models for RAG (and why the giants aren’t it)#
The intuition that bigger models give better answers for RAG is wrong. In RAG, the model gets the relevant context along with the query. It needs to read, understand, and faithfully synthesize information that’s already in the prompt (not from its parametric memory). That completely changes the requirements: instruction‑following ability, reading comprehension quality, and inference latency matter more than encyclopedic knowledge. General knowledge benchmarks like MMLU‑Pro measure what the model remembers, and in RAG, retrieval compensates for that anyway.
Qwen3.5‑35B‑A3B (397B total parameters, 3B active per token, Apache 2.0) is, for most production RAG workloads, the sweet spot. Three billion active parameters means you can deploy it on a single GPU with quantization (FP8 or 4‑bit), giving sub‑second inference latency on simple queries. The native 262k context window (extendable past a million with YaRN) covers practically any retrieval scenario. Its IFBench score of 76.5 – the best among all open‑source or commercial models – confirms it follows complex instructions better than anyone else (including GPT‑5.5, which scores 75.4). And the MoE architecture with Gated Delta Networks cuts KV cache consumption on long contexts – exactly where RAG operates.
The think/no‑think toggle, unique to the Qwen family, is something no commercial model offers, and it changes RAG’s economics. Simple factual retrieval queries like “who’s the CFO of company X?” run in no‑think mode: fast and cheap. Queries that need multi‑step reasoning, like “compare revenues over the last three quarters and identify trends,” activate think mode with adaptive depth. You pay for reasoning only when you actually need it. In a RAG pipeline processing millions of queries a month (where 70‑80% are straightforward retrieval), the savings are substantial.
If you need more reasoning horsepower, Qwen3.5‑122B‑A10B (122B total, 10B active, same context window, native multimodal) hits 86.6 on GPQA Diamond and 86.7 on MMLU‑Pro – enough active parameters for complex synthesis tasks while staying deployable on mid‑range hardware. Native multimodality means RAG over documents containing charts, diagrams, and photos (something most commercial models charge as a premium feature).
Qwen3‑8B (8B dense, 8.8 million downloads, Apache 2.0) is the choice when you need predictable latency and simplified deployment. Being a dense model (not MoE), there’s no variation in active parameters per token, which means consistent latency. Those 8.8 million downloads aren’t an accident: it’s the most deployed open‑source model for RAG in production, with the biggest ecosystem of fine‑tuning tools and the most quantized variants available.
DeepSeek V4 Flash (284B total, 13B active, 1M context window, MIT license) is what you pick when your use case demands ultra‑long context. If your RAG pipeline needs to process dozens of retrieved documents at once (fifty or more pages in context), the 1M token window with Hybrid Attention (CSA + HCA) is irreplaceable. Hybrid Attention cuts FLOPs on 1M‑token contexts to 27% of what conventional architectures would use, and KV cache to 10%. With 88.1 on GPQA Diamond and 86.4 on MMLU‑Pro, it delivers near‑Pro quality at a fraction of the inference cost.
GLM‑5.1 (roughly 300B‑400B total, 15B‑20B active, 200k context, MIT license) brings something no other model offers: Dynamic Sparse Attention with a built‑in indexing mechanism (index_topk=2048, index_n_heads=32). The model selectively attends to the most relevant tokens in the context using an internal index – which is literally what a RAG system needs. With 86.2 on GPQA Diamond and 63.5 on Terminal‑Bench 2.0, it shows strong agentic capability in technical contexts.
The giant models (DeepSeek V4 Pro with 49B active, Qwen3.5‑397B‑A17B with 17B active, Kimi K2.6 with 32B active) have their place on general benchmarks, but for RAG, their inference cost per query makes them economically unviable in most production scenarios. DeepSeek V4 Pro, which hits 90.1 on GPQA Diamond and ties commercial models on SWE‑Bench, costs three to four times more per query than the Flash version for marginal gains on RAG tasks. In a pipeline processing millions of queries, that difference turns into tens of thousands of dollars a month with no noticeable improvement in RAG answer quality.
What fine‑tuning buys you that no API ever will#
The strongest argument for open‑source models in RAG is control. With a commercial model, you can tweak the system prompt, provide few‑shot examples, and adjust the temperature. With Qwen3.5‑35B‑A3B or Qwen3‑8B, you can fine‑tune on your domain data, your response patterns, your definitions of relevance. LlamaFactory supports over 100 models with LoRA, QLoRA, and full fine‑tuning. Models with 3B‑8B active parameters fine‑tune in hours on a single GPU. Models with 49B active parameters (like DeepSeek V4 Pro) need multi‑GPU infrastructure and days of training to get the same result.
Your embedding model can be customized too. Qwen3‑Embedding‑0.6B (5.8 million downloads, 32k context, 100 languages, Matryoshka Representation Learning for dimensional flexibility) can be fine‑tuned on your own query‑document pairs to directly improve retrieval. BGE‑m3, with 18.2 million downloads, supports dense, sparse, and multi‑vector search, and also takes fine‑tuning on domain data. You train the embedding to understand your documents instead of relying on a generic one.
The reranking model completes the trio. Qwen3‑Reranker‑0.6B (instruction‑aware, 32k context, 1.5 million downloads) and Qwen3‑Reranker‑4B (higher quality, still efficient on a single GPU) form, together with embeddings from the same family, a coherent pipeline where embedding, reranking, and generation share vocabulary and representations. That reduces the semantic gap between retrieval and generation (one of the most common problems in RAG pipelines). BGE‑reranker‑v2‑m3, with 8.3 million downloads, is the battle‑tested alternative for multilingual environments.
DSPy, the Stanford framework now at version 3.2, lets you optimize prompts, retrieval parameters, and model weights simultaneously. Instead of manually tuning each component of the pipeline, you define success metrics and DSPy searches for the optimal configuration automatically. That kind of optimization is impossible with commercial APIs, because you don’t have access to the weights, the gradients, or even full control over the model’s internal prompts.
Picture this: your company has 10,000 contracts with industry‑specific clauses, terms defined in local regulations, and references to technical standards a generic model never saw during training. A generic model, no matter how capable, will mess up terminological nuances that distinguish similar instruments in the context of, say, a conversion clause. A model fine‑tuned on your corpus recognizes those nuances because it was trained to. That’s the difference between a technically acceptable answer and one a domain expert can sign off on without revisions.
Customization goes beyond the generator. You tune the embedding model on your query‑document pairs, improving retrieval quality at the source. You tune the reranking model on your relevance judgments, teaching the system what “relevant” means in your context. You modify the chunking strategy to respect your document structure (chapters, sections, subsections) instead of slicing into fixed‑size chunks. Every one of these optimizations is out of reach when you depend on an API that offers a single endpoint with a handful of parameters.
Architecture that actually works#
A RAG pipeline with open‑source models, as of April 2026, is solid production engineering. For ingestion and parsing, LlamaParse and Apache Tika handle PDFs, DOCX, PPTX, and exotic formats with built‑in OCR. For chunking, semantic strategies (grouping by meaning) and document‑aware approaches (respecting section boundaries) have left old fixed‑size partitions in the dust. For embeddings, Qwen3‑Embedding‑0.6B gives you 100 languages, 32k context, and MRL for dimensional flexibility – all in 0.6B parameters that fit on any GPU. For vector storage, Milvus (Go and C++, native horizontal scaling via Kubernetes), Qdrant (Rust, advanced filtering), and Chroma (Python, quick prototyping) are mature and free.
Hybrid search (semantic + lexical with BM25) is the current gold standard, endorsed by Pinecone’s, Qdrant’s, and Milvus’s own documentation. Semantic search captures synonyms and meaning relationships but misses specific technical terms. Lexical search captures exact terms but misses nearby meanings. Combine them, rerank with Qwen3‑Reranker‑4B, and you get results neither can find alone.
Microsoft’s GraphRAG adds another layer: knowledge graphs extracted automatically from your documents. Instead of searching only by vector similarity, the system builds structured relationships between entities and uses them to answer global questions that plain vector RAG can’t address. The graphrag package is on PyPI, open‑source, and integrates naturally with open‑source LLMs.
For orchestration, LangChain (134k GitHub stars, version 1.2.15) and LlamaIndex (49k stars, version 0.14.21) offer mature abstractions for RAG pipelines with any model. Haystack (25k stars, version 2.28.0) is production‑focused with an explicit modular architecture. R2R (SciPhi‑AI) gives you hybrid search, knowledge graphs, and a production‑ready REST API, all under MIT. LangGraph lets you build agentic RAG workflows with durable execution, reasoning loops, and human‑in‑the‑loop. And DSPy, with its “program, don’t prompt” approach, automatically optimizes retrieval parameters, prompts, and model weights based on success metrics you define.
The decision that’s left#
Once you take quality off the table (because open‑source models have already matched or beaten commercial ones on RAG tasks, as Kimi K2.6 shows with its 92.5 F1 on DeepSearchQA, beating GPT‑5.5, Opus 4.7, and Gemini 3.1 Pro), what remains are questions of control, cost, and sovereignty.
Regulated industries (finance, healthcare, government, defense) have data residency requirements that make commercial APIs a non‑starter for RAG. Organizations operating across multiple jurisdictions face a maze of data protection laws that change from country to country. The only scalable solution is to keep data local. And the only way to do RAG with LLMs while keeping data local is to use open‑source models.
The choice is between control and dependency. Between data sovereignty and contractual promises. Between infrastructure you own and an API that can change prices, terms of use, and availability at any time. Between a model you can audit, fine‑tune, and scale as you need, and a model whose internal behavior is a black box.
Open‑source models for RAG have passed the promise phase. With Qwen3.5‑35B‑A3B scoring 76.5 on IFBench (better than any commercial competitor), DeepSeek V4 Flash offering 1 million tokens of context at 13B active parameters, and Qwen3‑8B racking up 8.8 million downloads in production, the quality already covers any RAG need you might have. If you’re still paying per token to hand your data over to someone else, it’s time to recalc.
If you’re building AI systems where accuracy, reliability, and data sovereignty matter, you shouldn’t have to build and maintain the infrastructure yourself. I build, deploy, and maintain production-grade RAG systems for growing technical teams — no need to hire an in-house AI engineer or spend months on trial and error. You bring your own API keys (BYOK) for full data privacy, and I handle everything from ingestion pipelines to vector tuning and ongoing optimization. Explore my managed RAG service here.