
(Antonio V. Franco)
I ran 135 celestial object classification tasks using three memory approaches. The result was counterintuitive.
It seems like common sense: if an artificial intelligence agent learns from its past experiences, it should become better over time. Each solved problem becomes a reference, a reusable pattern that accelerates and sharpens future decisions. This is precisely the intuition behind the ReasoningBank paper (Ouyang et al., ICLR 2026), a system that stores reasoning strategies in a memory bank and retrieves them when facing similar tasks. The promise is seductive and aligns with how human experts build expertise.
But what if, in certain scenarios, that very memory turns into a self-reinforcing bias? Could the mechanism designed to improve performance actually degrade it, locking the agent into a narrow set of overconfident habits? Those unsettling questions drove me to design and execute a complete benchmark of stellar classification using data from the Sloan Digital Sky Survey (SDSS) and a large language model, Qwen3.5. The experiment was tailored to probe exactly this tension between memory augmentation and cognitive distortion. The outcome was counterintuitive, revealing, and above all useful for anyone building AI systems that incorporate persistent memory.
I discovered that a naive memory implementation, the one described in the original ReasoningBank paper, slashed overall classification accuracy by 22 percentage points compared to a memory-free baseline. Only when I introduced a suite of careful curatorial mechanisms (consolidation, pruning, class-balanced retrieval, and confidence-aware fallback) did performance return to the baseline level. This recovery was both encouraging and sobering: in my specific domain, even the sophisticated memory did not surpass the agent without any memory. It simply stopped hurting. The experiment became a practical lesson in how memory should be designed, monitored, and continuously pruned, much like a garden that needs weeding to remain fertile.
Classifying Stars, Galaxies, and Quasars#
The SDSS has catalogued millions of celestial objects by measuring their brightness in five photometric bands (u, g, r, i, and z) and estimating their redshift. Redshift is a fundamental cosmological indicator: it reveals how fast an object is moving away from Earth and serves as a proxy for distance. Higher redshift means farther away and, typically, earlier in cosmic history. The task I posed to the model sounds deceptively straightforward. Given a set of photometric observations (five magnitude values and a redshift), assign the object to one of three categories: STAR, GALAXY, or QSO (quasar).
Each class inhabits a roughly distinct region of the five-dimensional feature space, but the boundaries are anything but crisp. Stars are nearby objects, showing redshifts close to zero and colors that span a wide but intermediate range. Their light is dominated by blackbody radiation from hot plasma, with absorption lines that reflect surface chemistry. Galaxies are vast collections of stars lying at moderate distances, with redshifts typically around 0.15. Their colors are redder on average, because they tend to contain older, cooler stellar populations, and their spectra are complex composites. Quasars are the extreme outliers. Powered by supermassive black holes accreting matter at ferocious rates, they shine with an intense ultraviolet excess and exhibit high redshifts (often above 1.0, with a median of about 1.2 in typical SDSS samples). Their photometric signature is unmistakable when the signal is strong, but it softens and blurs when the object is faint or when its light mixes with that of a host galaxy.
The real difficulty lies in the overlapping tails of these distributions. Some stars with unusual colors can masquerade as galaxies. Galaxies with active nuclei can mimic quasars. And quasars with weak UV excess can slip into the galaxy cloud. A classifier relying solely on photometric features must confront these ambiguous regions, and the quality of its decisions there depends on subtle pattern recognition that goes beyond simple rule-based heuristics. This is precisely where a memory of past reasoning could either illuminate the subtlety or, as I found, dangerously reinforce a mistaken shortcut.
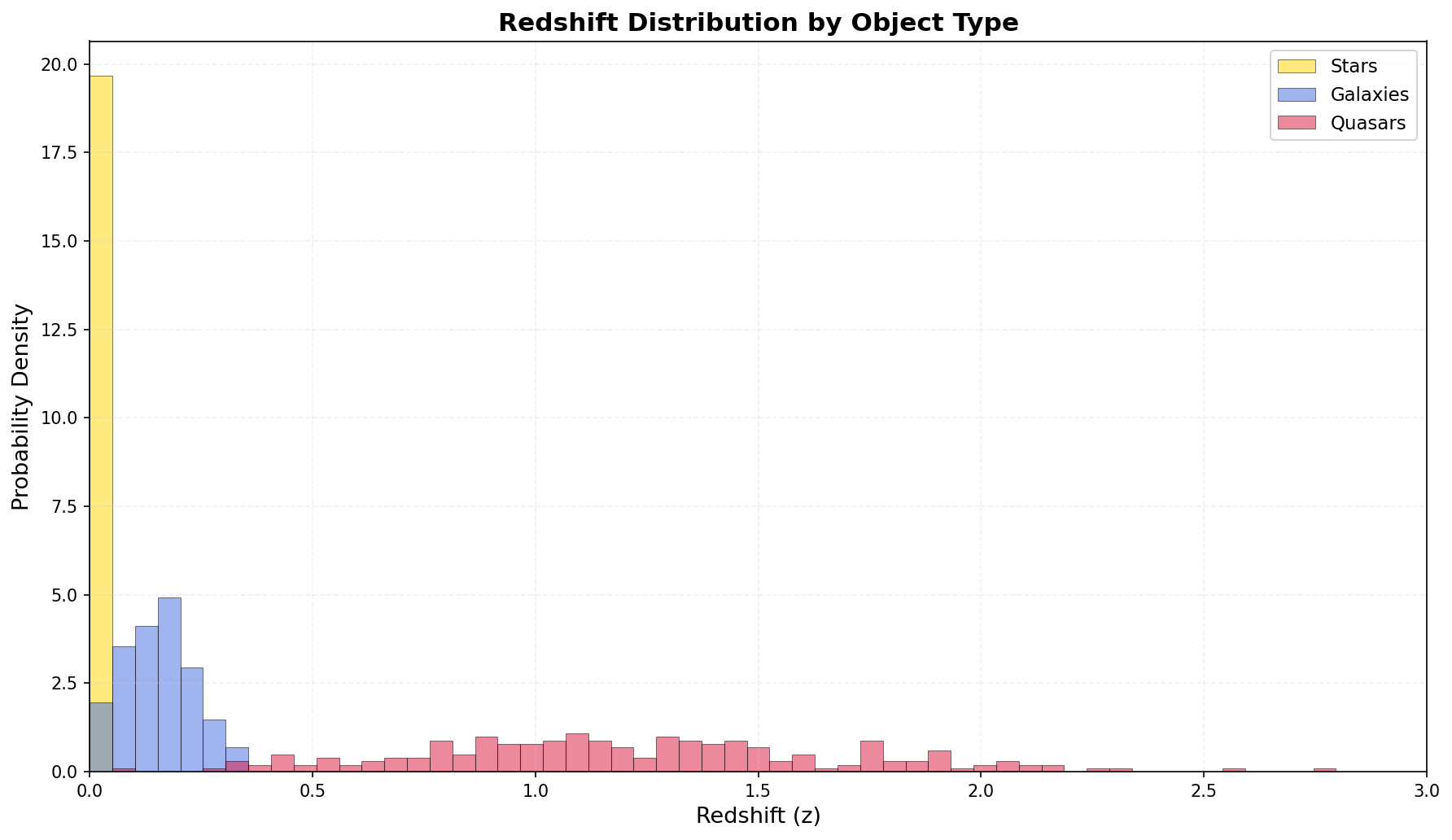
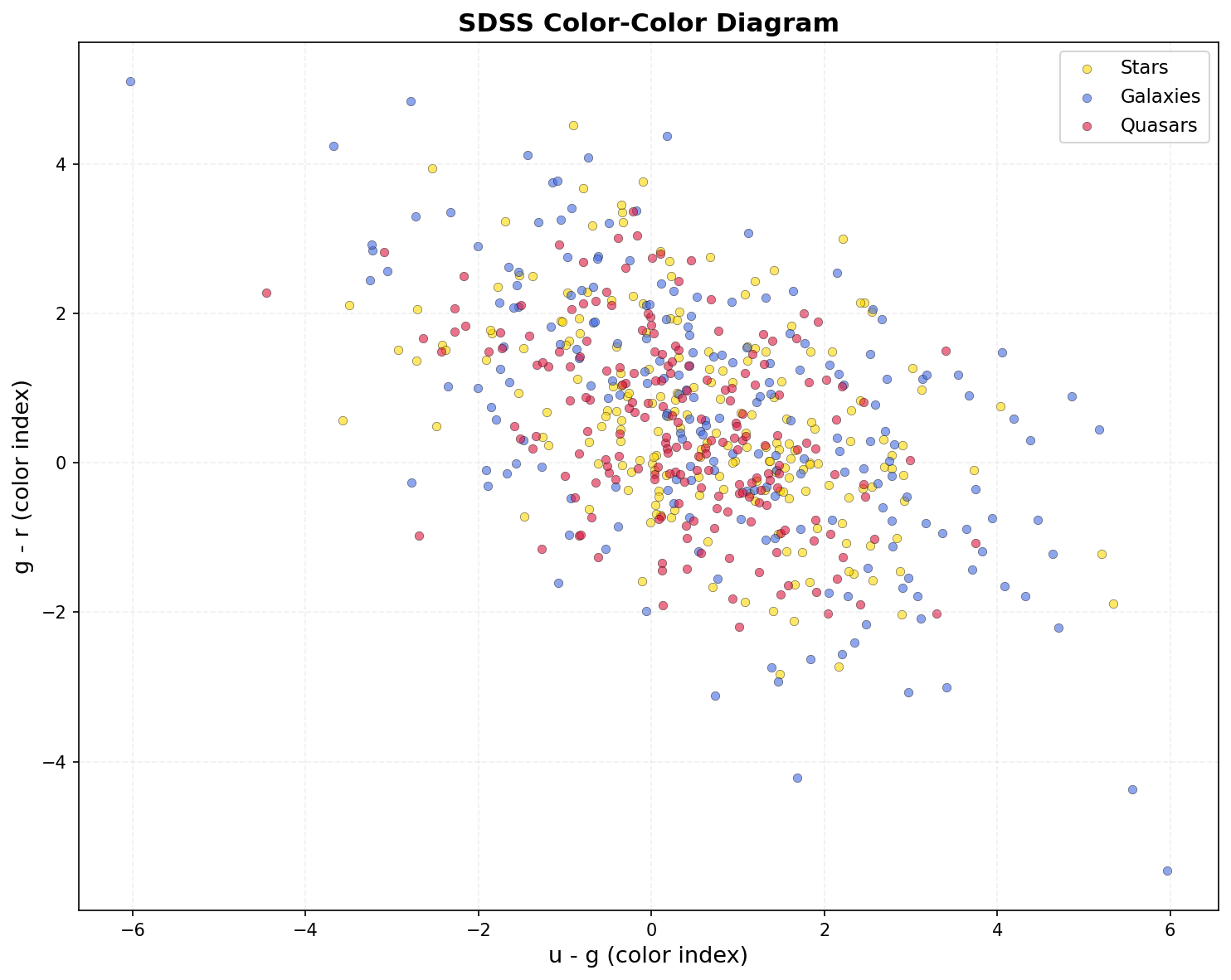
When I plot the redshift distribution of my balanced sample, the challenge becomes visual. The quasar curve stretches far to the right, but its left skirt sweeps back and mingles with the galaxy population. The stellar distribution hugs zero, yet some star-like objects at moderate redshift could easily be mistaken for compact galaxies. A memory system that stores spatial shortcuts (like “if redshift above 0.8, think quasar”) might excel on a subset while catastrophically failing on the overlapping region.
(Antonio V. Franco)
A color-color diagram deepens the story. By plotting the difference between the u and g magnitudes against the difference between g and r, I project the five-dimensional photometry onto two axes that capture a great deal of astrophysical information. Stars form a tightly knit main sequence stretching from blue to red. Galaxies clump in a redder zone but spill toward the blue side when they contain vigorous star formation. Quasars occupy a distinct cloud at the blue end, but a bridge of intermediate-color objects connects them to the galaxy region. This bridge is the killing ground for naive classifiers: objects in it could legitimately belong to either population. A good memory system needs to recognize that these bridge objects are inherently ambiguous and should trigger cautious, multi-hypothesis reasoning. A bad memory, as I will see, simply forces them into the majority habit it has learned.
(Antonio V. Franco)
Three Conditions, 45 Tasks Each#
I built a benchmark consisting of 135 classification tasks in total, 45 per condition, carefully sampled to include 15 stars, 15 galaxies, and 15 quasars each. The sampling used a fixed random seed and identical data across all conditions, guaranteeing that any difference in performance stems solely from the memory architecture and not from data variance. The three conditions were:
Baseline (no memory): The model receives only the photometric data and the classification instruction. It must reason from its pre-trained internal knowledge alone, without access to any record of previous tasks. This condition captures the innate capability of Qwen3.5 on my specialized astronomy challenge.
Traditional ReasoningBank: I replicated the memory system as described in the original paper. A flat embedding space, constructed from the sentence-transformers model all-MiniLM-L6-v2 (384 dimensions), stores the text of each correct answer. When a new query arrives, the system retrieves the single most similar past memory (k=1) and presents it as context to the language model. There is no consolidation, no pruning, no hierarchy. The bank grows monotonically with every successful classification, never forgetting and never curating. This is the “naive” memory condition.
RB-EC (ReasoningBank with Enhanced Curation): This is my improved architecture. It moves far beyond simple flat retrieval by integrating five core innovations. The Embedding Improvement Mechanism (EIM) creates multi-field embeddings that weight the title, description, and body of each memory item differently, capturing richer contextual cues. The Retrieval-Adaptive Task Typing (RATT) dynamically decides how many memories to retrieve (k between 1 and 3) based on a real-time complexity estimate. Consolidation via Embedding Similarity (CES) periodically clusters and merges near-duplicate memories after every 20 episodes, preventing the bank from fragmenting into exhaustive copies. Dual-Condition Cards (DCC) build higher-level macro-cards that bundle co-occurring micro-strategies, allowing the system to recognize that “this type of galaxy with a moderate redshift” often appears alongside “this quasar-like color” in the data. Finally, Pruning by Significance and Trajectory (PST) removes low-utility items while maintaining a hard floor of minimum memories per class, preventing catastrophic forgetting of rare patterns.
In addition to these five mechanisms, I embedded several operational safeguards that directly counter biases observed in the traditional memory. Class-balanced retrieval penalizes memory items from classes already overrepresented in the retrieval set, ensuring that a QSO-dominated bank cannot flood every query. A debiasing tracker monitors a rolling accuracy window and temporarily downweights items whose repeated use correlates with errors. Confidence-aware fallback activates when the model’s own certainty (as judged by token probability) drops below a threshold: it discards memory and falls back to zero-shot reasoning. An ambiguous task detector flags objects that lie in known boundary regions and triggers a more conservative retrieval strategy. And consolidation guardrails ensure that the merging and pruning steps never reduce the count for any class below a safe minimal level. Together, these additions transform memory from a passive logbook into an actively managed resource.
For all conditions, I used the Qwen3.5-9B language model, loaded with 8-bit quantization through the BitsAndBytes library. This reduced the model’s memory footprint sufficiently to run on a single NVIDIA A40 GPU with 48 GB of VRAM, while preserving output quality nearly indistinguishable from full-precision. I disabled the model’s built-in chain-of-thought “thinking” mode by setting the system prompt to /no_think, ensuring that any step-by-step reasoning was driven solely by the memory context I provided, not by the model’s internal deliberation. The entire benchmark ran on a RunPod Secure Cloud instance (one A40, 50 GB RAM, 9 vCPUs) at a cost of $0.44 per hour. Total wall-clock time was approximately 125 minutes, yielding a total compute cost of roughly $0.92.
Results: Traditional Memory Reduced Accuracy by 22 Percentage Points#
The headline result was as stark as it was surprising. The memory-free baseline correctly classified 36 out of 45 objects, achieving an accuracy of 80.0%. The traditional ReasoningBank, which simply retrieved the nearest past memory, managed only 26 correct (57.8%). Adding a naive memory had made the model substantially worse. The enhanced RB-EC system also scored 36 correct (80.0%), exactly matching the baseline. Memory did not have to hurt, but in my benchmark it did not (yet) help either.
Class-by-Class Breakdown#
A closer look at the individual classes reveals the internal dynamics of the collapse and recovery.
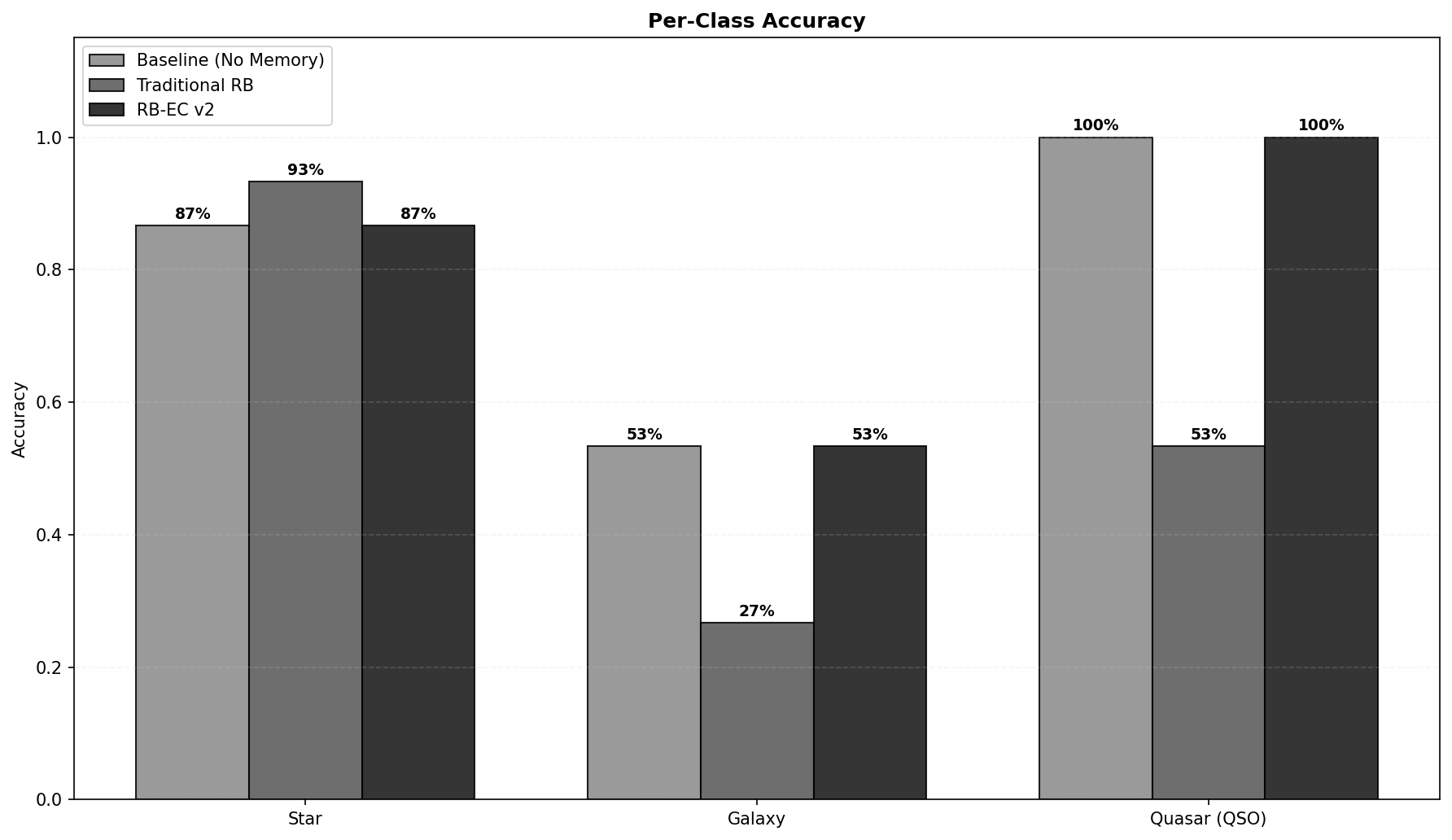
Quasar classification was flawless in the baseline and in RB-EC: 15 out of 15 correct. The traditional memory, however, misclassified nearly half of the quasars. The cause was a runaway QSO bias that took root early in the task sequence. The first several quasars in the sampling were spectroscopically unambiguous, and the system stored memories that strongly associated high redshift with the QSO class. When later tasks required classifying a galaxy with a moderate redshift (say, 0.3) or a star with an unusual blue hue, the retrieval mechanism fished out those QSO-laden memories. The model, primed by the retrieved context, overapplied the “high redshift equals QSO” rule, turning galaxies and even some ambiguous objects into false quasars. Over time, the bank accumulated more and more QSO-centric entries, deepening the rut.
Galaxies were the most difficult class across all conditions. Even the baseline and RB-EC reached only 53.3% accuracy, meaning nearly half of all galaxies were misclassified. The traditional memory collapsed to a catastrophic 26.7%. Galaxies sit in a naturally ambiguous zone of the photometric space. Their colors can overlap with both red stars and blue quasars, and without spectral features, a fraction of misclassifications is essentially unavoidable in a purely photometric task. A memory system that lacks mechanisms to handle such inherent uncertainty simply amplifies the worst tendencies.
Stars present a fascinating counterpoint. The traditional memory achieved 93.3% accuracy on stars, the best mark of any condition. This seems like a triumph until you consider that this stellar success came at the expense of the other two classes. The same memory that aced stars was aggressively mislabeling galaxies and quasars. This is a textbook example of class imbalance created internally by the memory dynamics: easy classes come to dominate the bank and then re-prime the model to see everything through their lens.
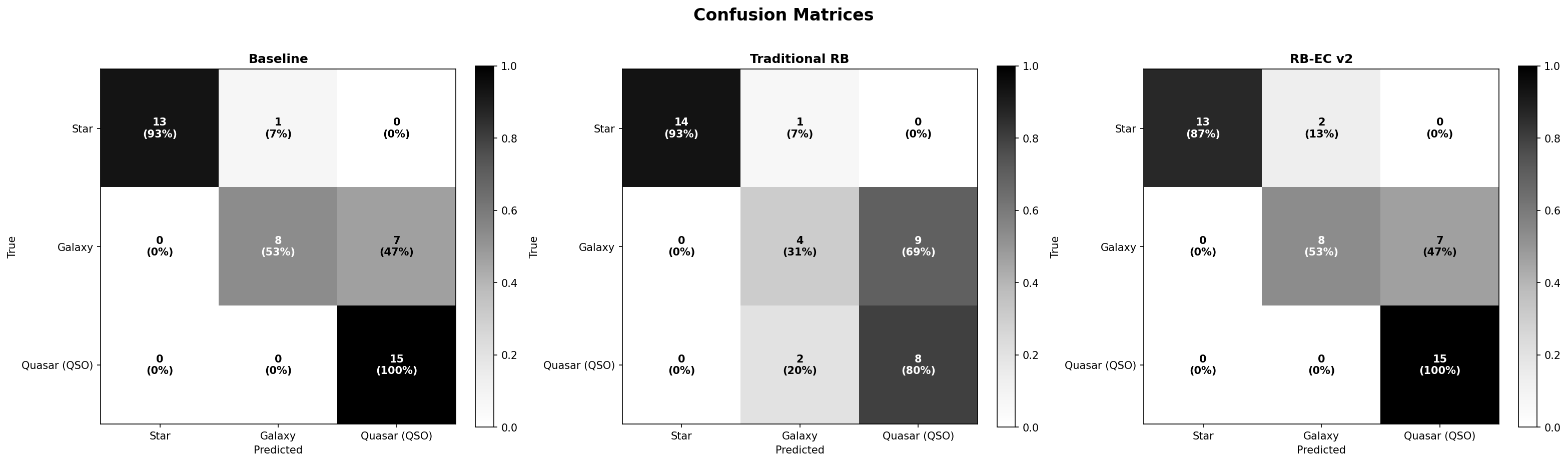
Confusion Matrices#
The confusion matrices lay bare the exact patterns of error.
In the baseline, errors are limited and structurally predictable. Seven galaxies were called quasars, one star was called a galaxy, and one star was incorrectly labeled a quasar. All other predictions were correct. There is a clear galaxy-to-quasar confusion corridor, attributable to the overlap in color space, and a tiny amount of stellar spillage. This is the signature of a model making honest mistakes in a genuinely ambiguous landscape.
(Antonio V. Franco)
The traditional ReasoningBank matrix is messy and disturbing. Nine galaxies became quasars, two galaxies and three quasars were so uncertain that the model output an UNKNOWN label (something the baseline never did), two quasars were flipped to galaxies, and one star drifted into the galaxy column. The memory did not just amplify the baseline’s confusion; it injected new, systematic errors. The UNKNOWN labels are particularly telling: the model, flooded with contradictory memory cues, lost confidence and refused to commit to any class.
(Antonio V. Franco)
RB-EC restored the confusion pattern to near-baseline cleanliness. Seven galaxies were misclassified as quasars, two stars became galaxies, and that was it. The additional noise that plagued the traditional memory was eliminated. The safeguards had successfully identified and neutralized the QSO-bias loop, allowing the model to rely on memory when useful and to ignore it when it was not.
(Antonio V. Franco)
Memory Bank Growth and Behavior#
The evolution of the memory bank size tells a story of two philosophies.
(Antonio V. Franco)
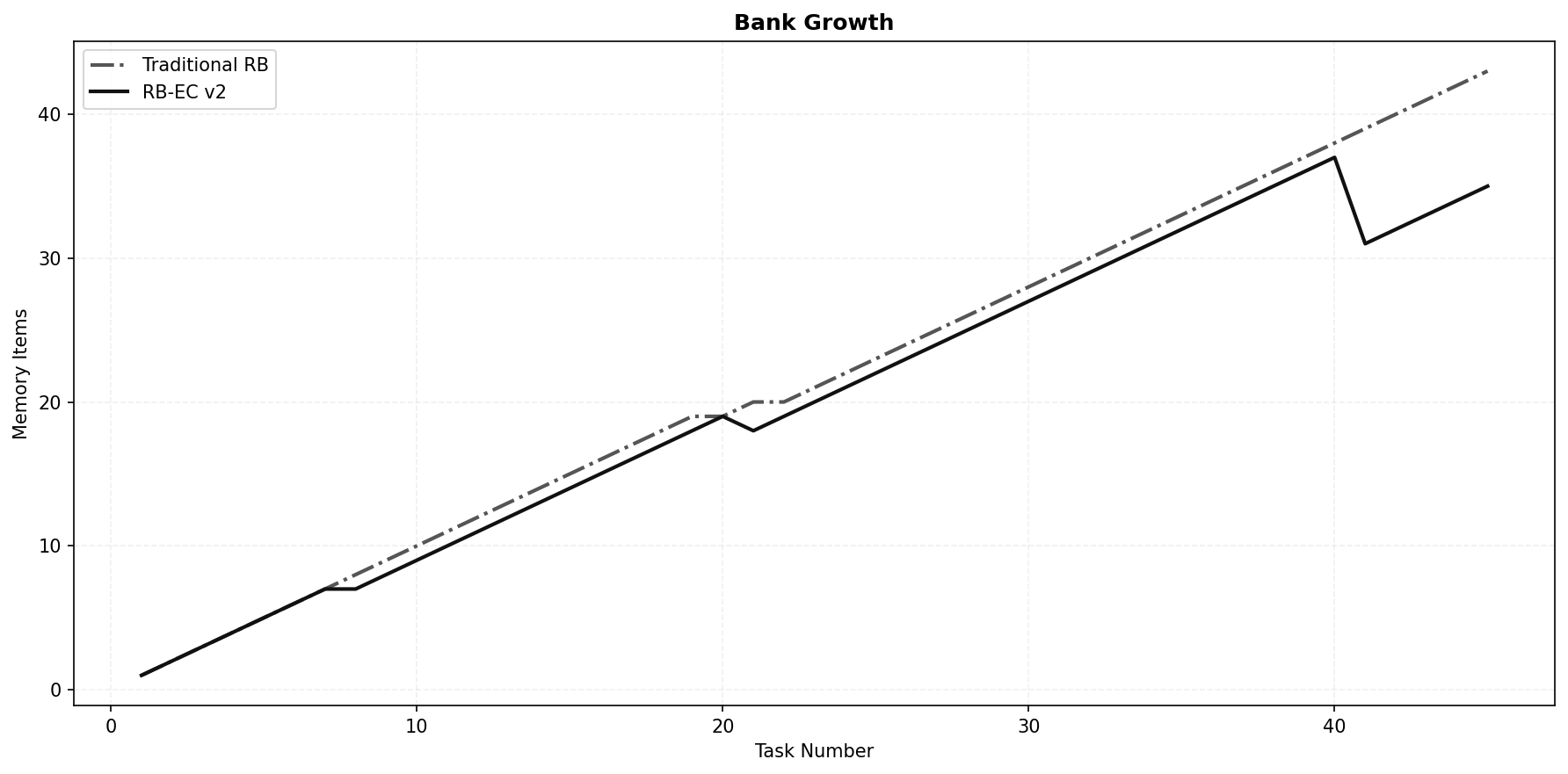
The traditional bank grew monotonically from 0 to 43 items, adding a new entry after every correct classification. There was no mechanism to say “this memory is redundant” or “this memory is outdated.” The bank became a bloated, noisy attic. RB-EC, in contrast, grew to 19 items by task 20, then experienced its first consolidation event (CES and PST acting in tandem), which merged and pruned the bank down to 18. It resumed growing, reached 37 by task 40, and was pruned sharply again to 31. It finished at 35 items, 19% smaller than the traditional bank. More importantly, those 35 items were of vastly higher quality, having been filtered for diversity, recency, and minimal per-class representation.
This dynamic is the direct consequence of the consolidation guardrails and the class-balanced pruning. By capping the memory not just in total size but in per-class saturation, RB-EC prevented any single class from colonizing the retrieval space. The bank remained a pluralistic library, not a monologue.
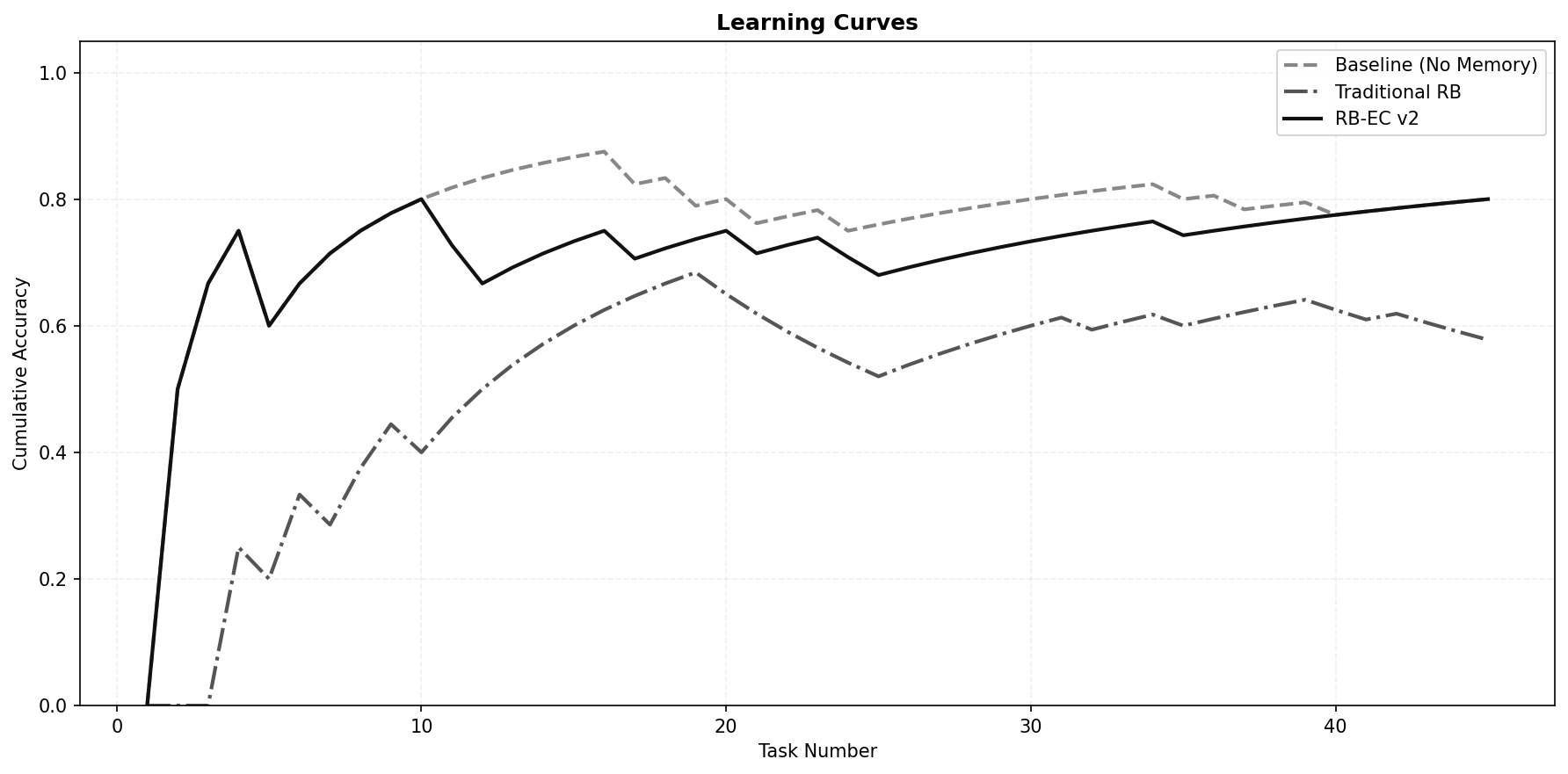
Learning Curves#
The accuracy over time provides perhaps the most intuitive narrative.
(Antonio V. Franco)
The baseline started with a few early errors, learned the task distribution quickly, and hovered around 80 to 87% accuracy for the remainder of the run. Its performance was stable and predictable. The traditional memory began miserably (0% on the first three tasks, as the empty bank provided no help and the model struggled with the domain). As the bank filled, accuracy climbed and peaked around 68% near task 19. Then the curve turned downward. The growing bank, now saturated with QSO memories, began to poison subsequent judgments. Accuracy declined and settled at 57.8%, well below its own earlier peak. This is the classic pattern of a self-corrupting memory system: short-term gain followed by long-term degradation.
RB-EC mirrored the baseline almost perfectly, rising rapidly, oscillating within a narrow band, and maintaining a slight upward trend. The consolidation resets caused momentary small dips, but they were followed by quick recoveries. The system never entered a self-destructive spiral because the safeguards continually pruned the bank and balanced retrieval.
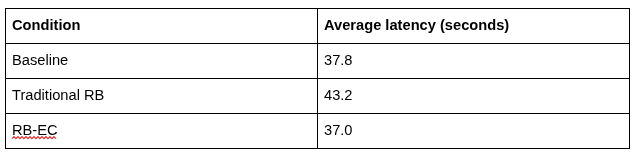
Latency#
Memory retrieval comes with a computational cost, and I measured it carefully.
(Antonio V. Franco)
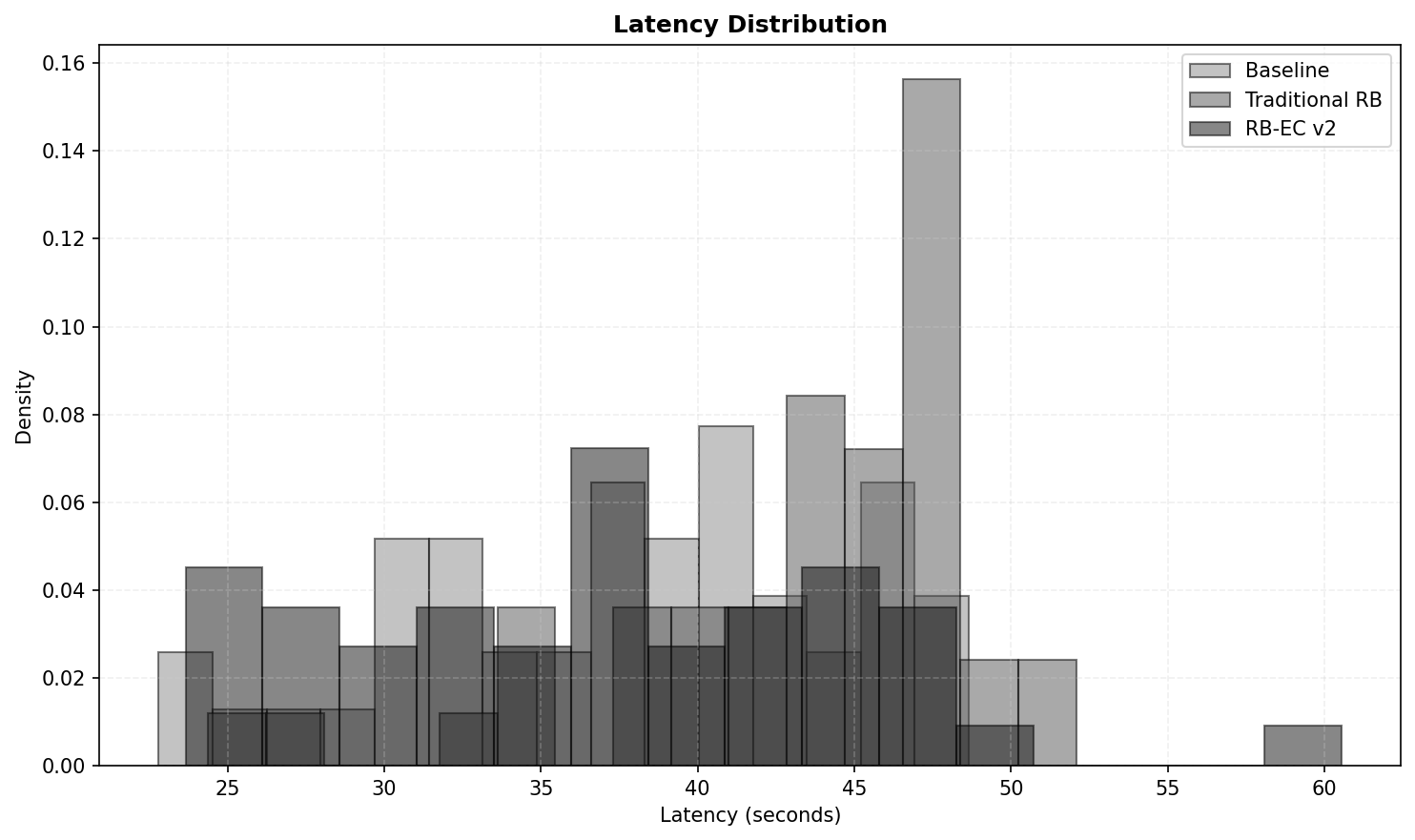
At first glance, it seems paradoxical that the most sophisticated memory system runs fastest. The explanation is twofold. First, the consolidated, pruned bank in RB-EC is significantly smaller and cleaner, which makes the similarity search faster (even with adaptive k, the search space is smaller and the retrieved items are more relevant). Second, the traditional memory, while using the simplest possible retrieval (k equal to 1, nearest neighbor), must search through a bloated, noisy bank that grows unchecked for the entire experiment. The time spent sifting through an ever-expanding, low-quality memory pool outweighs the overhead of adaptive retrieval and consolidation. Efficiency in memory is not just about retrieval complexity; it is about how well the memory contents are curated.
What I Learned#
1. Uncurated memory is worse than no memory at all#
The most counterintuitive finding is that the traditional ReasoningBank, exactly as proposed, dropped accuracy by an absolute 22 percentage points relative to a baseline that used no memory. The common assumption that “any memory is better than none” is dangerously false for AI agents in certain domains. When a memory system stores experiences without quality filtering, without consolidation, and without debiasing, it creates a closed loop of self-reinforcing error. The agent does not just recall good strategies; it recalls and amplifies its own biases. In my case, the bias was class-specific: easy quasars flooded the bank and contaminated retrieval for galaxies and stars. The consequence was a system that grew worse the more it “learned.”
2. Consolidation and pruning are not optional features; they are survival necessities#
RB-EC matched the baseline with a bank that was 19% smaller. The periodic consolidation (CES) merged redundant items, while the pruning (PST) removed low-relevance entries. The guardrails ensured that no class was erased. The result was a memory bank that supported accurate classification across all classes without introducing destructive noise. This underscores a vital design principle: memory in machine learning agents must be treated as a living, curated resource, not a passive append-only log. Without curation, memory becomes mental clutter.
3. Domain characteristics dictate memory usefulness#
The original ReasoningBank paper demonstrated improvements on software engineering benchmarks like WebArena and SWE-Bench. Those tasks are open-ended, with a vast array of possible strategies, and strategies for different bugs do not typically compete with one another. My domain is fundamentally different. Stellar classification has only three classes, and the feature space is heavily overlapped. A strategy that works for quasars can actively mislead when applied to galaxies. This suggests that memory systems are most beneficial in domains with high strategy diversity and low inter-class strategy competition. In domains with tight class coupling (like classification into a small, overlapping set of categories), memory can become a liability unless extraordinary care is taken.
4. Class-balanced retrieval is a powerful debiasing tool#
The single most impactful safeguard within RB-EC was the class-balanced retrieval inside the internal _diversify_by_class mechanism. Instead of simply taking the k most similar memories, the system penalizes items from classes already represented in the retrieval set. This simple rule breaks the QSO-dominance cycle. Even when the bank contains many QSO memories, the retrieval step ensures that galaxies and stars also get a voice in the context provided to the model. The result is a balanced committee of memories, not an echo chamber.
5. Latency and quality can coexist#
A common concern with sophisticated memory mechanisms is that they will slow down inference to unacceptable levels. My benchmark refutes this. RB-EC was the fastest condition, not despite its complexity but because its curation reduced the search space and eliminated fruitless retrieval steps. Good design does not trade speed for quality; it achieves both by working smarter with less.
The Hertzsprung-Russell Diagram as a Physical Anchor#
To ground my results in astrophysical reality, it is worth placing them against the Hertzsprung-Russell (HR) diagram, the foundational chart of stellar astronomy. The HR diagram plots intrinsic brightness against surface temperature and reveals the physical basis for stellar classification. Main-sequence stars, red giants, white dwarfs, and other evolutionary stages each occupy distinct branches.
(Antonio V. Franco)
When the model’s memory items refer to concepts like “position on the main sequence” or “red giant branch,” they are drawing on a physically meaningful coordinate system. The quality of the agent’s reasoning depends on correctly mapping photometric colors and redshifts onto this framework. A memory entry that misinterprets a red galaxy as a cool star is, at root, a failure to respect the physical distinctions encoded in the HR diagram. The RB-EC system’s success in matching the baseline implies that its memories remained physically coherent, without the class contamination that plagued the naive bank.
How to Reproduce#
All code, data sampling, and evaluation scripts are openly available in the project repository: https://github.com/AntonioVFranco/reasoningbank-ec-benchmark
The benchmark ran on a RunPod A40 Secure Cloud pod (at $0.44 per hour) with the following software environment:
- transformers (version >= 4.46.0), accelerate (>= 0.34.0)
- sentence-transformers
- auto-gptq, optimum
- matplotlib, scipy, numpy
Authentication tokens for Hugging Face and RunPod were supplied as environment variables and were never hardcoded in the source. The model was loaded in 8-bit mode to fit comfortably on the A40’s 48 GB of VRAM. The entire run, including model loading and chart generation, took just over two hours and cost under one dollar.
Conclusion#
Giving memory to a language model is not an automatic improvement. It is an architectural decision that demands the same rigor as designing the model itself: with consolidation, with pruning, with debiasing, with guardrails. The RB-EC system demonstrated that a carefully engineered memory can be harmless, preserving baseline accuracy without introducing bias. In more complex, diverse domains, it may well surpass the baseline. But the central lesson is that memory is an active system that must be managed. It is not a passive deposit box for experiences, and when treated as one, it quickly becomes a trap.
My counterintuitive result (a 22-percentage-point drop from naive memory) is not a condemnation of memory-augmented AI. It is a cautionary tale and a call to engineering discipline. The path forward lies in understanding that memory is a living resource, shaped by its own contents, and that the architecture around it must be as thoughtfully designed as the memory itself.
The next step is to test these principles in richer domains, with more classes, higher-dimensional features, and greater task diversity. If RB-EC can match a strong baseline in an adversarial classification setting, what can it achieve in a setting where the classes are truly separable and strategies do not compete? That question will drive my next investigation.
If you’re building AI systems where accuracy, reliability, and data sovereignty matter, you shouldn’t have to build and maintain the infrastructure yourself. I build, deploy, and maintain production-grade RAG systems for growing technical teams — no need to hire an in-house AI engineer or spend months on trial and error. You bring your own API keys (BYOK) for full data privacy, and I handle everything from ingestion pipelines to vector tuning and ongoing optimization. Explore my managed RAG service here.